Chapter 2 Simple Linear Regression
This chapter contains content from Sleuth Chapters 7 and 8.
2.1 The variables
Suppose we have a quantitative response variable \(y\) that we want to relate to an explanatory (aka predictor) variable \(x\). For now, we will assume that \(x\) is also quantitative.
2.2 EDA for SLR
We should always start with basic data exploration tools when starting a statistical analysis. For our quantitative variables, this could mean looking at histograms and basic summary stats to understand variable distributions, check for interesting cases (e.g. outliers), and determine whether variables have missing values (NAs).
Next, we can explore the “bivariate” relationship between our response \(y\) and predictor \(x\) by creating a scatterplot of \(y\) (y-axis) against \(x\) (x-axis). When enough data exists, adding a smoother trend line can also be useful which (basically) shows the average response value as we move along the x-axis. Smoothers shouldn’t be used with smaller data sets as they will just “connect the dots” on the page. They are also sensitive (i.e. pulled) to points at the tails of the \(x\) and \(y\) distributions.
Things to consider when assessing a scatterplot are
- relationship form linear? curved?
- direction positive (as \(x\) goes up, so does \(y\))? negative (as \(x\) goes up, \(y\) goes down)? both? neither?
- relationship strength weak (lots of scatter in the form)? strong (very little scatter)? fan shaped (scatter of \(y\) changes as \(x\) changes)?
- unusual cases are there isolated points (outliers)? are there points not following the trend shown by most other points?
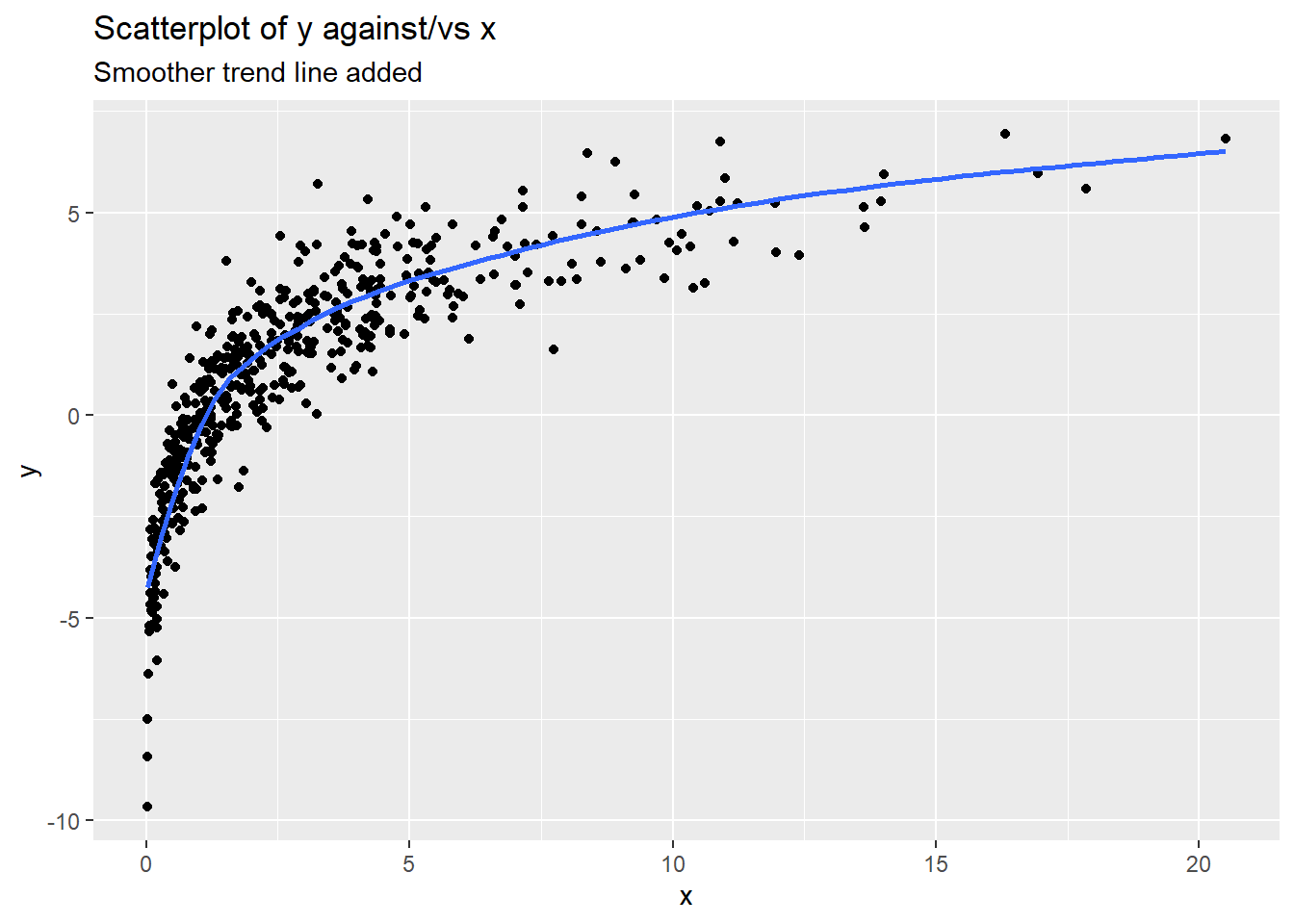
The scatterplot example below shows the following:
- relationship form: curved (concave down)
- direction: overall positive, though the relationship flattens out for larger values of \(x\)
- relationship strength: fairly strong trend shown, but there is more variation of the response around the blue trend line as \(x\) gets larger (e.g. points “fit” the trend line better at lower \(x\) compared to higher \(x\))
- unusual cases Nothing stands out as not fitting the overall pattern. There are cases in the “tails” of the x/y distributions, but these cases still follow the trend of the majority of cases.
A basic scatterplot can be created in R with the plot:
plot(y ~ x, data = my_data, main = "my title")where my_data is a data frame with variables called y and x (use whatever names are appropriate for your data!).
The R pacakge ggplot2 can also create nice scatterplots:
ggplot(my_data, aes(x = x, y = y)) +
geom_point() +
labs(title = "my title")We can add more layers to a ggplot by just adding another command, for example, adding a smoother to the above command with geom_smooth(se = FALSE).
2.3 The model form
This section describes the SLR model for a particular population of interest. Another way to frame the model is that it describes a hypothetical data generating process (DGP) that was used to generate the sample of data that we have on hand.
Let \(Y_i\) be the response from unit \(i\) that has explanatory (aka predictor) value \(x_i\). There are two equivalent ways to express the SLR model for \(Y\):
Conditional normal model: Given a value \(x_i\), the response \(Y_i\) follows a normal model with mean and SD given below: \[ Y_i \mid x_i \sim N(\mu_{y\mid x} = \beta_0 + \beta_1 x_i, \sigma) \]
Mean + error: Statisticians are more likely to use a model specification that expresses \(Y\) as a function of the expected value/mean of \(Y\) plus an error term that models variation in responses around the mean: \[\begin{equation} Y_i = \beta_0 + \beta_1 x_i + \epsilon_i \ \ \ \ \ \epsilon_i \sim N(0, \sigma) \end{equation}\]
Both expressions of the SLR model above say the same thing:
- Linear Mean: \(\mu_{y\mid x} = E(Y \mid x) = \beta_0 + \beta_1 x\) describes the population mean value of \(Y\) given a predictor value \(x\). This mean value varies linearly with \(x\) and the population parameters are \(\beta_0\) and \(\beta_1\).
- Constant SD: \(SD(Y\mid x)=\sigma\) describes the SD of \(Y\)’s in the population around a given mean value \(\mu_{y\mid x}\). The fact that this SD does not depend on the value of \(x\) is called the contant variance, or homoscedastic, assumption.
- Normality: The shape of population response values around \(\mu_{y\mid x}\) is described by a normal distribution model.
Finally, one last assumption is made for the SLR model:
- Indepedence: Given a predictor value of \(x\), all responses \(Y\) occur independently of each other.
There are a total of three parameters in the SLR model:
- the two mean parameters \(\beta_0\) and \(\beta_1\)
- the SD parameter \(\sigma\)
2.3.1 Interpretation
For a SLR model:
- \(\beta_0\) is the mean response when the predictor value is 0 since \(\mu_{y \mid 0} = \beta_0 + \beta_1(0) = \beta_0\).
- \(\beta_1\) tells us how the mean response changes for a one unit increase in \(x\)
2.3.2 Example: Woodpecker nests
We want to model nest depth (cm) in a tree cavity as a function of ambient air temperature (Celsius). Our SLR model for this relationships says that, given an ambient air temp \(x_i\), a randomly selected nest will have a depth \(Y_i\) that is modeled as \[ Y_i = \beta_0 + \beta_1 x_i + \epsilon_i \ \ \ \ \ \epsilon_i \sim N(0, \sigma) \] This means that depth is normally distributed with a mean of \(\mu_{depth \mid temp} = \beta_0 + \beta_1 (temp)\) and a SD of \(\sigma\). According to this model, each 1 degree increase in air temp is associated with a mean change in nest depth of \(\beta_1\) cm.
2.4 Theory: Estimation
Let’s consider taking a random sample of size \(n\) of responses and predictor values from our population (or DGP) for which the SLR model holds: \((x_1, Y_1), \dotsc, (x_n, Y_n)\). The notation here, \((x_i, Y_i)\) implies that the predictor value \(x_i\) is fixed, but \(Y_i\) is a random variable that is generated from the SLR model described in Section 2.3. The estimation problem is that we need to use the sample of size \(n\) to estimate the SLR model parameters \(\beta_0\), \(\beta_1\) and \(\sigma\).
Once we observe a sample of size \(n\), then we can use the SLR model to determine the probability of observing the sample. This probability, which depends on the actual model parameters \(\beta_0\), \(\beta_1\) and \(\sigma\), is called a likelihood function. We plug the observed data into this function, then find the parameters values that maximize the function using calculus. For a SLR model, this process yields the following maximum likelihood estimators (MLE) of our parameters: \[ \hat{\beta}_1 = \dfrac{\sum_{i=1}^n (x_i - \bar{x})(Y_i - \bar{Y})}{\sum_{i=1}^n (x_i - \bar{x})^2} \ \ \ \ \ \hat{\beta}_0 = \bar{Y} - \bar{\beta}_1 \bar{x} \ \ \ \ \ \hat{\sigma} = \sqrt{\dfrac{\sum_{i=1}^n (Y_i - \hat{y}_i)^2}{n-2}} \] where \(\hat{y}_i = \hat{\beta}_0 + \hat{\beta}_1 x_i\) is the predicted value of \(y\) given the value \(x_i\).
2.4.1 Sampling Distributions for SLR estimates
The sampling distribution of a model estimate (\(\hat{\beta}_0\) or \(\hat{\beta}_1\)) is constructed by:
- fix a set of predictor values: \(x_1, \dotsc, x_n\)
- for each fixed \(x_i\), generate a response \(Y_i\) from \(N(\beta_0 + \beta_1 x_i, \sigma)\)
- compute the MLE’s \(\hat{\beta}_0\) and \(\hat{\beta}_1\) from the observed sample from (2)
- repeat 2-3 lots of times, then the distribution of the estimates from part (3) show the sampling distribution of the slope or intercept estimate.
Using probability theory, we can show that the sampling distributions of both \(\hat{\beta}_0\) and \(\hat{\beta}_1\) are approximately normal when \(n\) is “large enough” (thanks to the CLT): \[ \hat{\beta}_i \sim N(\beta_i, SD(\hat{\beta}_i)) \]
- Unbiased: We see that the expected value (mean) of \(\hat{\beta}_i\) is the parameter \(\beta_i\), meaning it is an unbiased estimator. (It doesn’t systematically over- or under-estimate the parameter of interest.)
- Standard error: We end up estimating the SD in the sampling distribution given above. The SEs for each mean parameter estimate are \[ SE(\hat{\beta}_1) = \hat{\sigma}\sqrt{\dfrac{1}{(n-1)s^2_x}} \ \ \ \ \ SE(\hat{\beta}_0) = \hat{\sigma}\sqrt{\dfrac{1}{n} + \dfrac{\bar{x}^2}{(n-1)s^2_x}} \]
2.5 Example: Nest depth
We will revisit the woodpecker nesting data first described in Section 2.3.2.
2.5.1 Load data
Let’s suppose these 16 nests are a random sample of all nests in the collection region. The command head(dataname) produces a view of the first 5 rows of data.
## temp depth
## 1 -6 21.1
## 2 -3 26.0
## 3 -2 18.0
## 4 1 19.2
## 5 6 16.9
## 6 10 18.1## [1] 12 22.5.2 EDA for SLR
Start with univariate exploration:
## temp depth
## Min. :-6.00 Min. :10.50
## 1st Qu.: 0.25 1st Qu.:12.03
## Median :10.50 Median :16.85
## Mean :11.00 Mean :16.36
## 3rd Qu.:21.75 3rd Qu.:18.38
## Max. :26.00 Max. :26.00
Graphically explore the (“bivariate”) relationship between temp and depth with a scatterplot using the command plot(y,x). Here is the plot version:
plot(depth ~ temp, # y ~ x variables
data = wpdata, # data
pch = 16, # makes filled circles
xlab = "air temperature (C)", # x-axis label
ylab = "nest depth (cm)", # y-axis label
main = "woodpeckers scatterplot") # title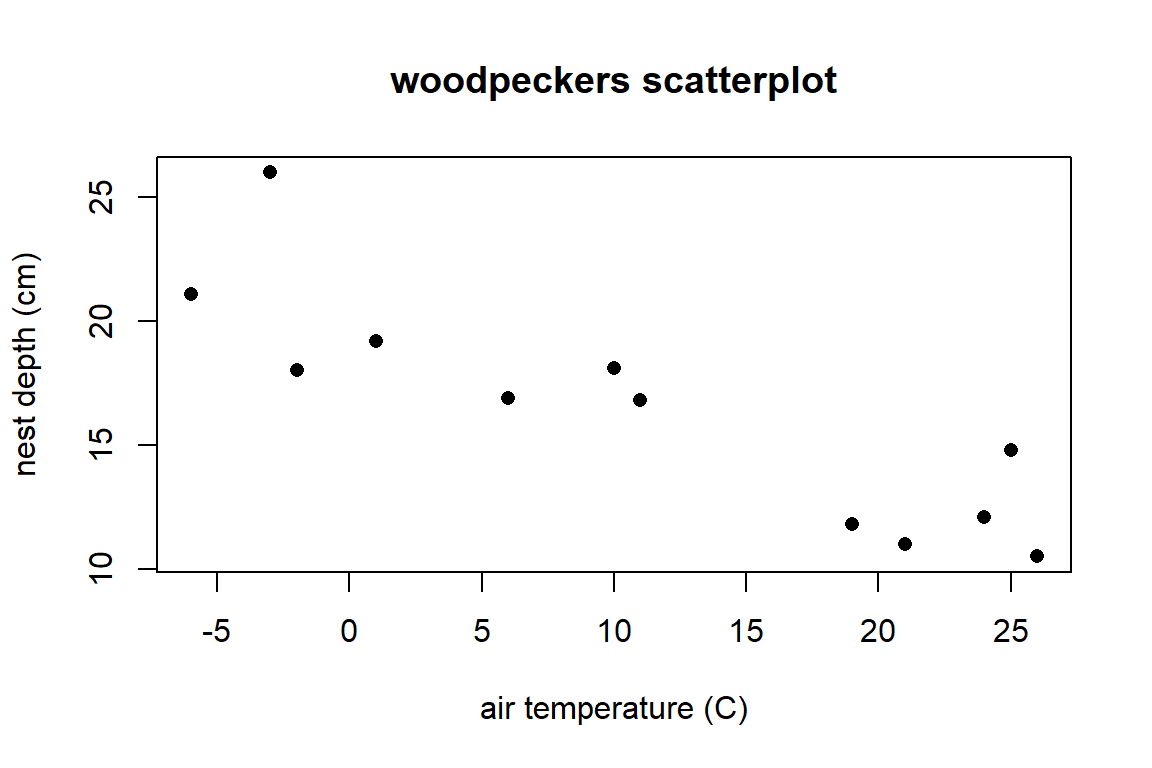
Here is the ggplot2 version with labs added to change labels and title:
library(ggplot2)
ggplot(wpdata, aes(x = temp, y = depth)) + # x and y variables
geom_point() + # point geometry (default is filled circles)
labs(x = "air temperature (C)", # x-axis label
y = "nest depth (cm)", # y-axis label
title = "woodpeckers scatterplot") # title
2.5.3 The least squares line (the estimated SLR model):
You fit the linear model with mean \(\mu_{Y \mid x} = \beta_0 + \beta_1 x\) with the linear model function lm(y ~ x, data = ).
##
## Call:
## lm(formula = depth ~ temp, data = wpdata)
##
## Coefficients:
## (Intercept) temp
## 20.1223 -0.3422We have mean parameter estimates: \[ \hat{\beta}_0 = 20.122 \ \ \ \ \hat{\beta}_1 = -0.342 \] Interpretation?!
Slope: According to this fitted model, a 1 degree increase in temp is associated with an estimated 0.342 cm decrease in mean nest depth. (In the next sections, we will estimate this effect with a confidence interval.)
Intercept: At 0 degree temp, we estimate an average nest depth of 20.122 cm.
2.5.4 Additional lm information
The object wood_lm is called a linear model object in R. We can use this object to add the regression line to an existing base R plot of the data using the abline command.
plot(depth ~ temp, data = wpdata, pch = 16,
xlab = "air temperature (C)", ylab = "nest depth (cm)",
main="regression of depth on temp")
abline(wood_lm)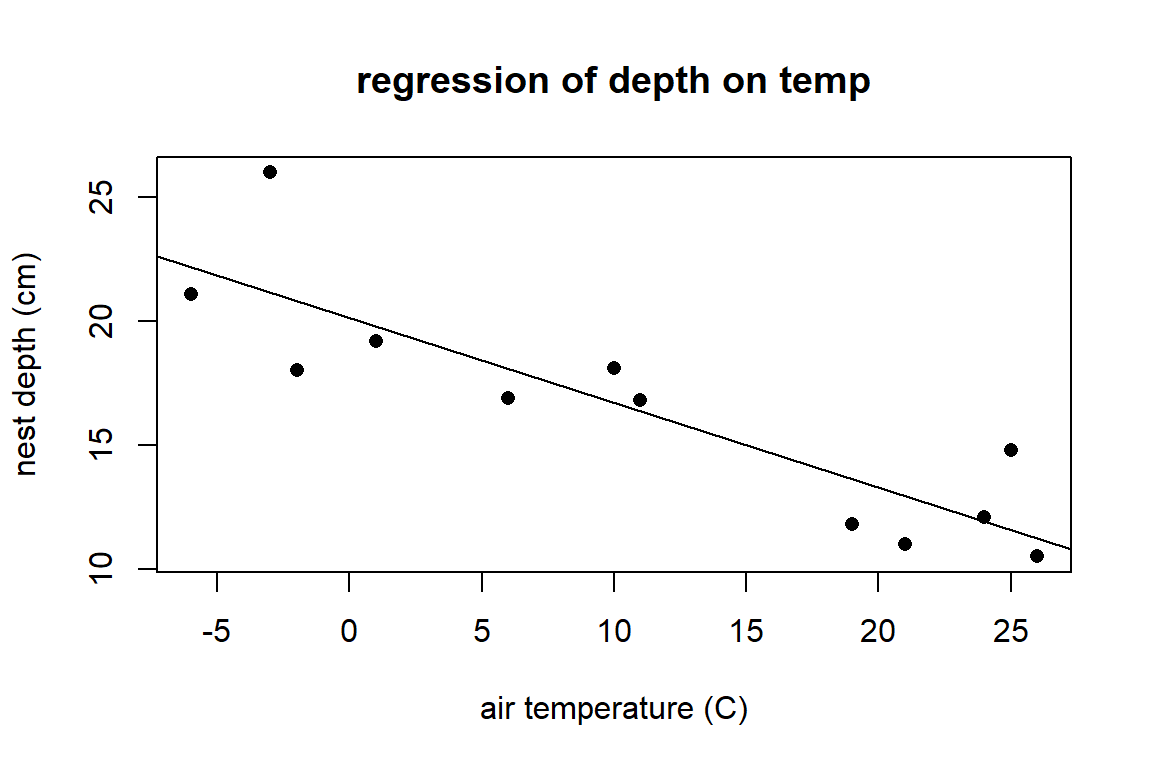
The ggplot2 package contains a geom_smooth geometry to add this SLR line:
ggplot(wpdata, aes(x=temp, y = depth)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE) +
labs(x = "air temperature (C)", y= "nest depth (cm)",
title= "woodpeckers scatterplot")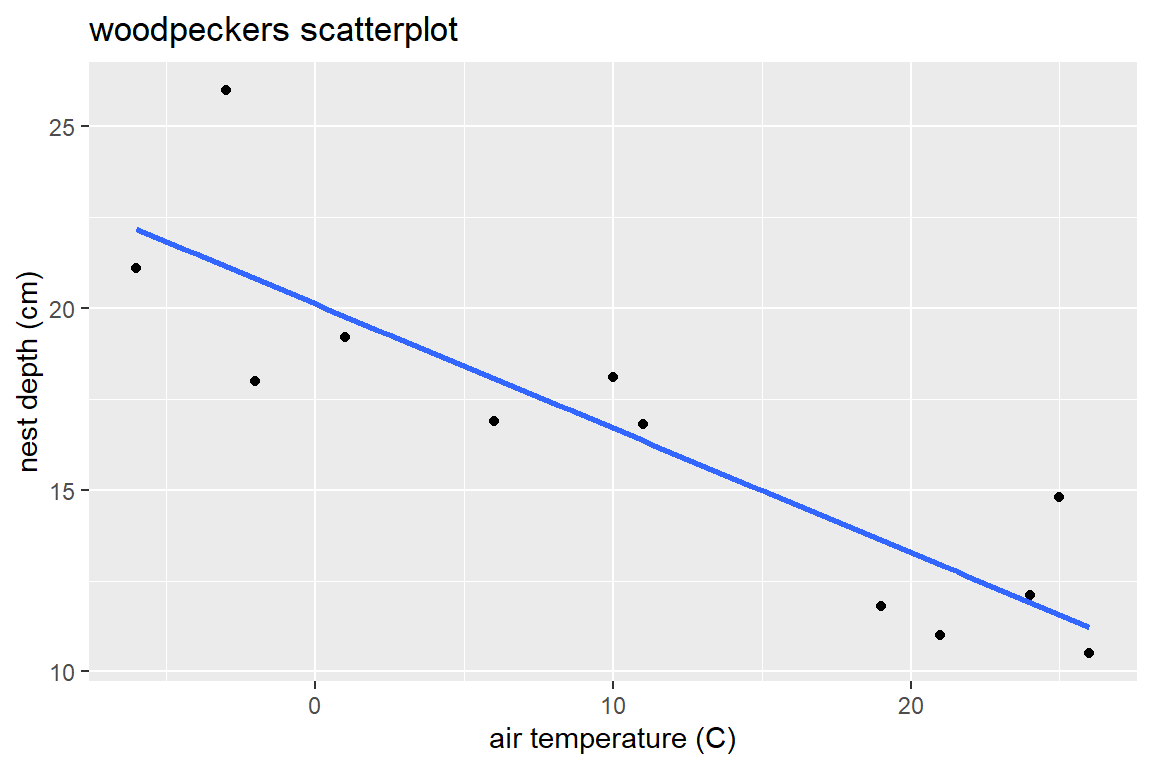
With geom_smooth, you need to specify the type of method used to relate \(x\) to \(y\). Adding se=FALSE removes a confidence interval for the mean trend. Notice that the aes aesthetic given in the ggplot function specifies the x and y variables to plot. The geom’s that follow this part of the command use this aes to create points and an estimated line.
Our linear model object wood_lm has lots of other information associated with it, including the coefficient values, fitted values (\(\hat{y}_i\)), and residuals (\(y_i - \hat{y}_i\)):
## $names
## [1] "coefficients" "residuals" "effects" "rank"
## [5] "fitted.values" "assign" "qr" "df.residual"
## [9] "xlevels" "call" "terms" "model"
##
## $class
## [1] "lm"## (Intercept) temp
## 20.1222838 -0.3421773## 1 2 3 4 5 6 7 8
## 22.17535 21.14882 20.80664 19.78011 18.06922 16.70051 16.35833 13.62091
## 9 10 11 12
## 12.93656 11.91003 11.56785 11.22567## 1 2 3 4 5 6 7
## -1.0753477 4.8511843 -2.8066384 -0.5801065 -1.1692199 1.3994894 0.4416667
## 8 9 10 11 12
## -1.8209148 -1.9365602 0.1899718 3.2321491 -0.7256736There are also functions that act on lm objects like
## 1 2 3 4 5 6 7 8
## 22.17535 21.14882 20.80664 19.78011 18.06922 16.70051 16.35833 13.62091
## 9 10 11 12
## 12.93656 11.91003 11.56785 11.22567## 1 2 3 4 5 6 7
## -1.0753477 4.8511843 -2.8066384 -0.5801065 -1.1692199 1.3994894 0.4416667
## 8 9 10 11 12
## -1.8209148 -1.9365602 0.1899718 3.2321491 -0.7256736vcov(wood_lm) # variance and covariance matrix of beta estimates - more on this in the next section! ## (Intercept) temp
## (Intercept) 0.88406062 -0.039081046
## temp -0.03908105 0.0035528222.6 SLR model simulation
2.6.1 Simulation function
This chunk contains code that defines our function reg.sim that simulates \(n\) responses from a given regression model and given set of \(n\) predictor values \(x\). You won’t need to create any functions like reg.sim in Stat 230, but take Stat 220 (Data Sci) to learn more about writing your own R functions!
reg.sim <- function(x, beta0, beta1, sigma, grph=T)
{
# function takes a sample of responses y generated from the given model/x values
# returns estimated intercept and slope
# x = explantory variable
# beta0, beta1 = true model intercept and slope
# sigma = true model SD
# grph = print simulation graphs (y vs. x)? (default is true)
n<- length(x)
muy.x <- beta0 + beta1 * x
# simulate some y's, then fit lm using these y's:
y <- rnorm(n, muy.x,sigma)
mylm <- lm(y~x)
# plot data, LS line, true line
if (grph){
plot(x,y,xlab="x",ylab="simulated y values",pch=16, ylim=c(0,30))
legend("topright",legend=c("Population line", "Sample line"),col=c("red","black"),lty=c(1,1),lwd=2)
abline(mylm,lwd=2)
abline(beta0,beta1,lwd=2,col="red")
}
return(list(b0=mylm$coefficients[[1]], b1=mylm$coefficients[[2]] ))
}2.6.2 Run the function once
Let’s use the function from (1) above. We will use the \(n=12\) temps (x-values) from the woodpeckers data and assume that the true model is:
\[\mu(y \mid x) = 20 - 0.4x\]
(red line below) with \(\beta_0=20\), \(\beta_1=-0.4\), and \(\sigma=2\). In the code below I use the set.seed() command to “fix” the random number generator so I get the same answer each time this is run (so my answer in the handout is reproduced each time this file is compiled).
wpdata<- read.csv("https://math.carleton.edu/kstclair/data/woodpeckers.csv")
set.seed(77)
reg.sim(x = wpdata$temp, beta0 = 20, beta1 = -.4, sigma = 2)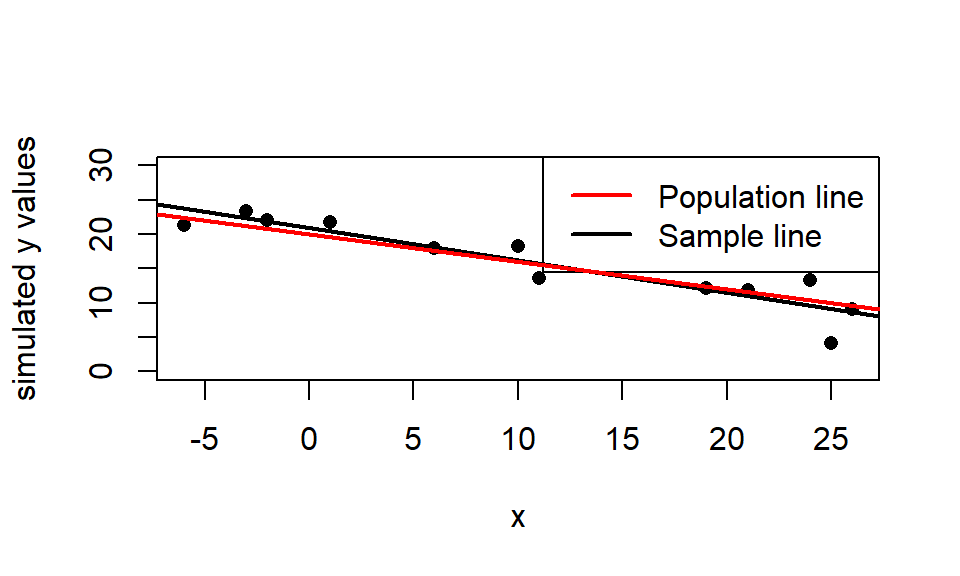
## $b0
## [1] 20.8893
##
## $b1
## [1] -0.4682368For this simulated sample (with seed of 77), the estimated regression line is \(\hat{\mu}(y \mid x) = 20.889 - 0.468x\) (black line).
2.6.3 Simulated sampling distribution for \(\hat{\beta}_1\)
We will now use the replicate command to generate 1000 different samples which create 1000 different estimates of \(\beta_1\). A histogram of these estimates simulates the sampling distribution of estimated slope.
What is the shape of the sampling distribution? Where is the distribution centered? How variable are these estimated slopes.
set.seed(7) # just makes simulation reproducible
slopes<- replicate(1000, # simulation size
reg.sim( # function that is repeated
x = wpdata$temp,
beta0 = 20,
beta1 = -.4,
sigma = 2,
grph = F)$b1 # return just "b1" values
)
hist(slopes)
abline(v=-0.4,col="red", lwd=2)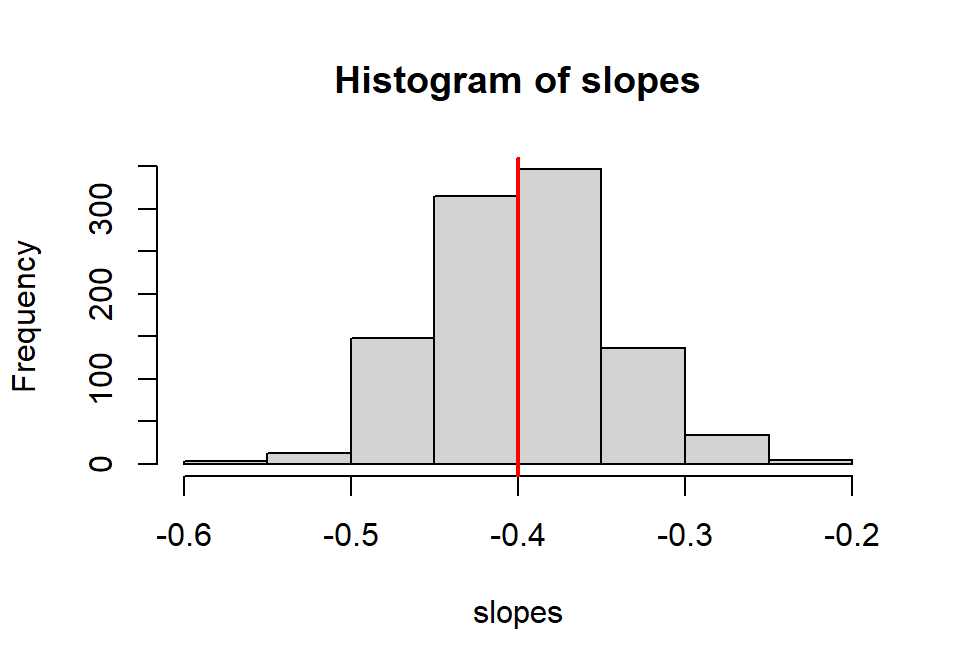
## [1] -0.3974248## [1] 0.052273152.6.4 Are slope and intercept estimates correlated?
In regression, it is not unusual to be interested in estimating a linear combination of our model parameters. An easy example of such a combination of parameters is the mean response for a given value \(x_0\) of the predictor: \[ \mu(y \mid x=x_0) = \beta_0 + \beta_1x_0 \] For a specific example, we may want to estimate the mean response (depth) for a temp of \(x_0=5\) degrees: \(\mu(y \mid x=5) = \beta_0 + \beta_1 5\). If we don’t know \(\beta_0\) and \(\beta_1\), then this mean parameter is a linear combination of two unknown parameters which we need to estimate.
The natural estimate of this is just the estimated mean response: \(\hat{\mu}(y \mid x=x_0)=\hat{\beta}_0 + \hat{\beta}_1x_0\). To assess how variable this estimate is (i.e. to get its SE) we need to understand how (if) the individual estimates \(\hat{\beta}_0\) and \(\hat{\beta}_1\) are correlated. We can use a simulation to look at this issue by generating 1000 samples from our model and plotting each \((\hat{\beta}_0,\hat{\beta}_1)\) pair for each sample.
How are estimated slope and intercept associated? Any ideas why?
set.seed(7) # this seed MUST match the seed used to get slopes!
intercepts<- replicate(1000, # simulation size
reg.sim( # function that is repeated
x=wpdata$temp,
beta0=20,
beta1=-.4,
sigma=2,
grph=F)$b0 # return just "b0" values
)
plot(intercepts, slopes)
abline(h=-.4,col="red")
abline(v=20,col="red")
title("Estimated slopes and intercepts")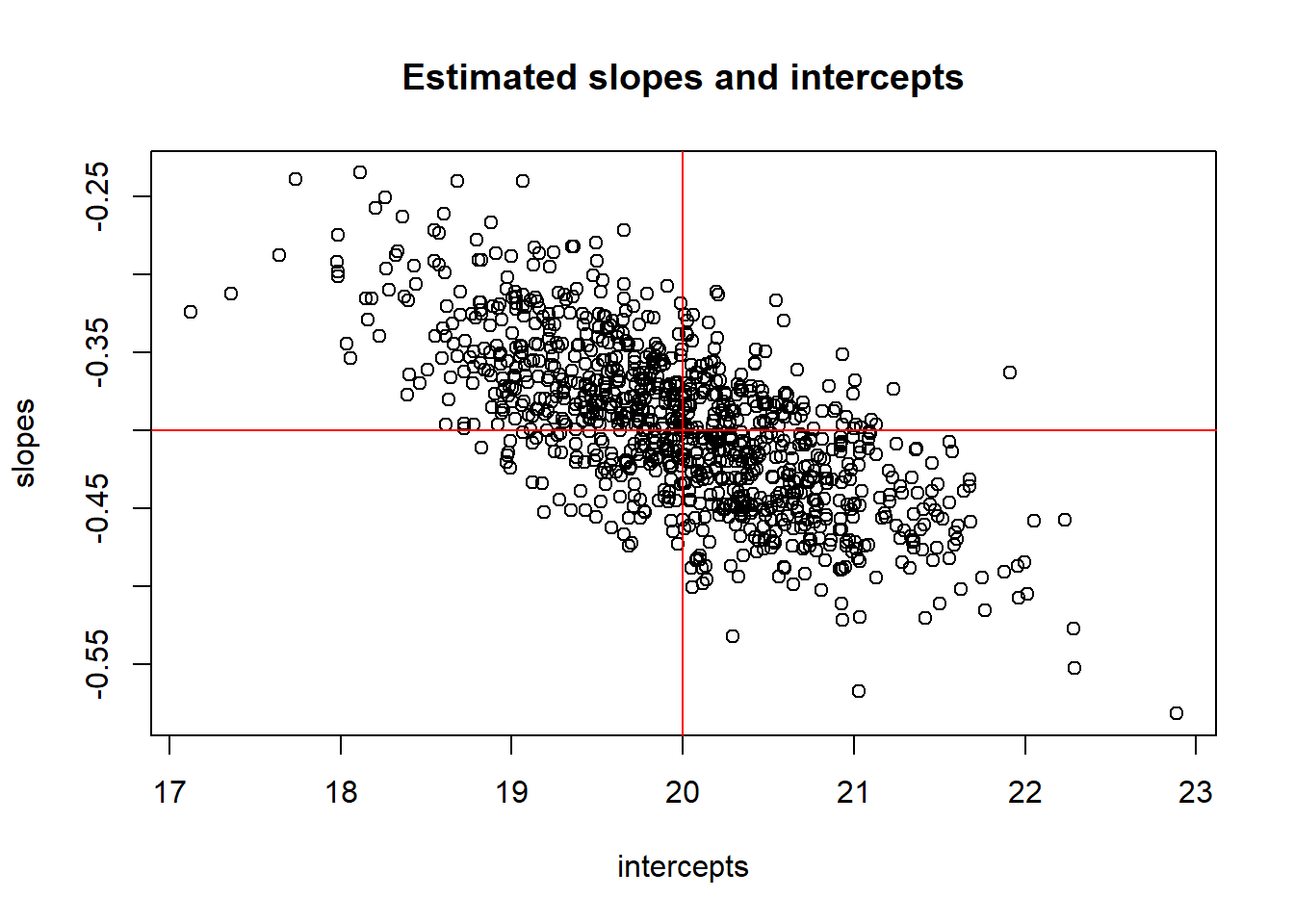
## [1] -0.6928231## [1] -0.028695042.7 Inference for mean parameters
In intro stats, you used \(t\) inference procedures for inference about population means since: (1) the sampling distribution of the sample mean was normally distributed and (2) we had to estimate its variability with a SE. The same goes for inference about the mean response parameters in a SLR model: \[ t = \dfrac{\hat{\beta}_i - \beta_i}{SE(\hat{\beta}_i)} \sim t_{df=n-2} \] Use a t-distribution with \(n-2\) degrees of freedom for inference about the mean parameters. The degrees of freedom are calculated as the sample size \(n\) minus the number of terms in \(\mu_{y \mid x}\) that you have to estimate with the data.
2.7.1 Confidence Intervals
To estimate either mean parameter with \(C\)% confidence, we have the general form \[ \hat{\beta}_i \pm t^* SE(\hat{\beta}_i) \] where \(t^*\) is the \((100-C)/2\) percentile from the t-distribution with \(df=n-2\) degrees of freedom.
2.7.2 Hypothesis tests
We can test the hypothesis \[ H_0: \beta_i = \beta^*_i \] with the following t-test statistic: \[ t =\dfrac{\hat{\beta}_i - \beta^*_i}{SE(\hat{\beta}_i)} \] where \(\beta^*\) is our hypothesized value of \(\beta\) (intercept or slope). The t-distribution with \(n-2\) degrees of freedom is used to compute the p-value that is appropriate for whatever \(H_A\) is specified.
The usual test results given by standard regression output tests whether a parameter value (intercept or slope) is equal to 0 vs. not equal to 0: \[ H_0: \beta_i = 0 \ \ \ \ \ H_A: \beta_i \neq 0 \] with a test stat of \[ t =\dfrac{\hat{\beta}_i - 0}{SE(\hat{\beta}_i)} \]
2.7.3 Example: Inference for nest depth coefficients
We will revisit the woodpecker nesting data first described in Section 2.5.
The summary command is used for statistical inference for the intercept \(\beta_0\) and slope \(\beta_1\):
##
## Call:
## lm(formula = depth ~ temp, data = wpdata)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.8066 -1.3321 -0.6529 0.6811 4.8512
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 20.12228 0.94024 21.401 1.11e-09 ***
## temp -0.34218 0.05961 -5.741 0.000188 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.335 on 10 degrees of freedom
## Multiple R-squared: 0.7672, Adjusted R-squared: 0.7439
## F-statistic: 32.96 on 1 and 10 DF, p-value: 0.0001875This output gives the mean parameter estimates in the Estimate column of the main table and their standard errors in the Std. Error column. In the intercept row we have:
\[
\hat{\beta}_0 = 20.122 \ \ \ \ SE(\hat{\beta}_0) = 0.94
\]
In the temp row, we have info about our slope parameter:
\[
\hat{\beta}_1 = -0.342 \ \ \ \ SE(\hat{\beta}_1) = 0.06
\]
The estimated model SD \(\sigma\) is given by Residual standard error:
\[
\hat{\sigma} = 2.335
\]
You should know how to verify (or find) the test stats and p-values for \(\beta_0\) and \(\beta_1\) given by the summary command if you are given the estimates and SEs. For the slope test \(H_0: \beta_1 = 0\) vs. \(H_A: \beta_1 \neq 0\) we get a \(t\) test stat of
## [1] -5.740312The p-value for this two sided test is the probability of being above +5.741 and below -5.741, or double the probability below -5.741 (since the t-distribution is symmetric around 0):
## [1] 9.373105e-05## [1] 0.0001874621A 95% confidence interval for the slope \(\beta_1\) is computed from the t distribution with 10 degrees of freedom:
## [1] 2.228139## [1] -0.4749994 -0.2093606## 2.5 % 97.5 %
## (Intercept) 18.0272874 22.2172802
## temp -0.4749868 -0.2093679The confint function gives the most accurate interval (no rounding error) but you need to know how to compute these CIs ``by hand.”
Summary: We have evidence that the effect of air temp on average nest depth is statistically significant (t = -5.741, df = 10, p = 0.0002). We are 95% confident that a 1 degree increase in air temp is associated with a 0.209 to 0.475 cm decrease in average nest depth.
2.7.3.1 broom package: Tidy lm output
The broom package contains functions that convert model objects (like a lm object) into “tidy” data frames. The tidy command summarizes model results:
## # A tibble: 2 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 20.1 0.940 21.4 0.00000000111
## 2 temp -0.342 0.0596 -5.74 0.000188Notice that the output object is called a “tibble” which is a type of data frame in R.
Here we can add confidence intervals for the model parameters to the output:
## # A tibble: 2 × 7
## term estimate std.error statistic p.value conf.low conf.high
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 20.1 0.940 21.4 0.00000000111 18.0 22.2
## 2 temp -0.342 0.0596 -5.74 0.000188 -0.475 -0.209The augment command augments the data frame used to create a lm with predicted values and residuals from the lm model:
## # A tibble: 6 × 8
## depth temp .fitted .resid .hat .sigma .cooksd .std.resid
## <dbl> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 21.1 -6 22.2 -1.08 0.272 2.42 0.0544 -0.540
## 2 26 -3 21.1 4.85 0.211 1.66 0.732 2.34
## 3 18 -2 20.8 -2.81 0.194 2.23 0.215 -1.34
## 4 19.2 1 19.8 -0.580 0.149 2.45 0.00632 -0.269
## 5 16.9 6 18.1 -1.17 0.0996 2.43 0.0154 -0.528
## 6 18.1 10 16.7 1.40 0.0840 2.41 0.0180 0.626The .fitted column gives the fitted values \(\hat{y}_i\) for each case and the .resid gives the residuals \(y_i - \hat{y}_i\).
2.7.3.2 Tools for displaying your model
As described in the Formatting Tables in Markdown (Section D.5), you can use the package stargazer to create a nice table of model results in your pdf. The entire R chunk to do this in a pdf doc format is shown below (but not evaluated in this html book). You will need to add the R chunk option results='asis' to get the table formatted correctly. I also include the message=FALSE option in the chunk below that runs the library command to suppress the automatic message created when running the library command with stargazer.
library(stargazer)
stargazer(wood_lm, header=FALSE, single.row = TRUE, title = "SLR of depth on temp")The kable function (from the knitr package) works well in all output environments (e.g. pdf, html, word). The input to this function needs to be a data frame, so we can use the tidy version of our model summary:
| term | estimate | std.error | statistic | p.value | conf.low | conf.high |
|---|---|---|---|---|---|---|
| (Intercept) | 20.122 | 0.94 | 21.401 | 0 | 18.027 | 22.217 |
| temp | -0.342 | 0.06 | -5.741 | 0 | -0.475 | -0.209 |
2.8 Inference for average or predicted response
2.8.1 Confidence intervals for \(\mu_{y \mid x}\)
Here we are interested in estimating not just a \(\beta\) with confidence, but we want to estimate the mean response for a given value of \(x_0\). For example, suppose we want to estimate the mean nest depth when the temp is \(x_0=8\) degrees. This mean parameter of interest is then: \[ \mu_{depth \mid temp=8} = \beta_0 + \beta_1 (8) \]
Our parameter of interest is \(\mu_{y \mid x_0} = \beta_0 + \beta_1 x_0\) where \(x_0\) is known and \(\beta\)’s need to be estimated. The natural estimator is just the fitted equation: \[ \hat{\mu}_{y \mid x_0} = \hat{\beta}_0 + \hat{\beta}_1 x_0 \] As will any estimator, we can measure the variability of this estimator with a SE: \[ SE(\hat{\mu}_{y \mid x_0}) = \hat{\sigma} \sqrt{\dfrac{1}{n} + \dfrac{(x_0 - \bar{x})^2}{(n-1)s^2_x}} \] Note! This SE depends on \(\pmb{x_0}\)! It is minimized when \(x_0\) equals the mean predictor value \(\bar{x}\) and it grows as \(x_0\) gets further from \(\bar{x}\). Estimation is most precise in the “middle” of the predictor range and becomes less precise at the “edges” (where we usually have less data).
A 95% confidence interval for the mean response \(\mu_{y \mid x_0}\) looks like \[ \hat{\mu}_{y \mid x_0} \pm t^*_{df=n-2}SE(\hat{\mu}_{y \mid x_0}) \]
2.8.2 Prediction intervals for new cases
To predict one individual’s future response \(Y\) for the predictor value \(x_0\), we just use the fitted equation: \[ pred_{y \mid x_0} = \hat{\beta}_0 + \hat{\beta}_1 x_0 \] (We use \(pred_{y \mid x_0}\) to remind us which predictor value as used for prediction.)
Recall that the SLR model assumes the \(Y\) values when \(x=x_0\) are normally distributed with mean \(\mu_{y \mid x_0}\) and SD \(\sigma\). The SE of this prediction at \(x_0\) takes into account (1) uncertainty in estimating the mean \(\mu_{y \mid x_0}\) and (2) variation in \(Y\)’s around the mean response (\(\sigma\)): \[ SE(pred_{y \mid x_0}) = \hat{\sigma} \sqrt{1 + \dfrac{1}{n} + \dfrac{(x_0 - \bar{x})^2}{(n-1)s^2_x}} = \sqrt{\hat{\sigma}^2 + SE(\hat{\mu}_{y \mid x_0})^2 } \] A 95% prediction interval for a future individual response at \(x=x_0\) looks like \[ pred_{y \mid x_0} \pm t^*_{df=n-2}SE(pred_{y \mid x_0}) \]
Predictions intervals feel and look similar to the mean response intervals above, but there is a very important conceptual difference: prediction means we are trying to “guess” at one individual response as opposed to the mean response of a large group of individuals. For example, if we want to understand nest depths for all nest build when temp is 8 degrees, then we care about estimating a fixed (but unknown) mean depth \(\mu_{depth \mid temp=8}\). If we see a bird starting to build a nest at 8 degrees, then we care about predicting this one, randomly determined depth \(Y\) using \(pred_{depth \mid temp=8}\) and would use a prediction interval.
2.8.3 Example: Inference for mean or predicted nest depth
Back to the woodpecker nesting data first described in Section 2.5.
We can get a 95% confidence interval for the mean nest depth at 8 degrees Celsius \(\mu(depth\mid temp=8)\) with the predict command with interval type confidence specified:
predict(wood_lm, # model object
newdata = data.frame(temp = 8), # new data
interval = "confidence", # interval type
se.fit = T) # show the SE for the estimated mean## $fit
## fit lwr upr
## 1 17.38487 15.83132 18.93841
##
## $se.fit
## [1] 0.6972406
##
## $df
## [1] 10
##
## $residual.scale
## [1] 2.33453The argument se.fit=T provides the SE of the mean response estimate. The estimated mean depth of all nests built at 8 degrees is 17.38 cm with a SE of 0.697 cm. We are 95% confident that the mean depth at 8 degrees is between 15.83 to 18.9 cm.
You can verify the computation of the SE and CI using summary stats for temp and the estimated parameter values from the summary command:
\[
\hat{\mu}_{temp \mid 8} = \hat{\beta}_0 + \hat{\beta}_1 (8) = 20.122 + (-0.342 )(8) = 17.385
\]
\[
SE(\hat{\mu}_{depth \mid 8}) = \hat{\sigma} \sqrt{\dfrac{1}{n} + \dfrac{(x_0 - \bar{x})^2}{(n-1)s^2_x}} = 2.335 \sqrt{\dfrac{1}{12} + \dfrac{(8-11)^2}{(12-1)11.809^2}} = 0.6972
\]
## [1] 12## [1] 11## [1] 11.80909## [1] 0.6972407## [1] 17.38484## [1] 15.83129 18.93839You can also include more than one predictor value temp in this function:
## temp
## 1 8
## 2 20## $fit
## fit lwr upr
## 1 17.38487 15.83132 18.93841
## 2 13.27874 11.35950 15.19798
##
## $se.fit
## 1 2
## 0.6972406 0.8613639
##
## $df
## [1] 10
##
## $residual.scale
## [1] 2.33453We can get a 95% prediction interval for the depth of one depth constructed at 8 degrees Celsius \(pred_{depth \mid temp=8}\) with the predict command with interval type prediction specified:
predict(wood_lm, # model object
newdata = data.frame(temp = 8), # new data
interval = "prediction") # interval type## fit lwr upr
## 1 17.38487 11.95617 22.81356We are 95% confident that a new nest built at 8 degrees will have a depth between 11.96 to 22.81 cm.
R does not give us the SE for prediction \(SE(pred(Y \mid x_0)) = \sqrt{\hat{\sigma}^2 + SE(\hat{\mu})^2}\) so we need to compute it by hand if we want its value: \[ SE(pred_{depth \mid 8}) = \sqrt{\hat{\sigma}^2 + SE(\hat{\mu})^2} = \sqrt{2.335^2 + 0.6972^2} = 2.436 \]
## [1] 2.436427The predicted depth of one nest build at 8 degress is 17.38 cm with a SE of 2.44 cm. The 95% prediction interval produced above can be verified as follows:
## [1] 17.38484## [1] 11.95614 22.813542.8.3.1 Adding confidence bands to a scatterplot
The geom_smooth function in ggplot2 adds a 95% confidence interval for \(\mu_{y \mid x}\) around the estimated mean line:
ggplot(wpdata, aes(x = temp, y = depth)) +
geom_point() +
geom_smooth(method = "lm") +
labs(x = "air temperature (C)", y= "nest depth (cm)",
title= "woodpeckers scatterplot with mean confidence interval")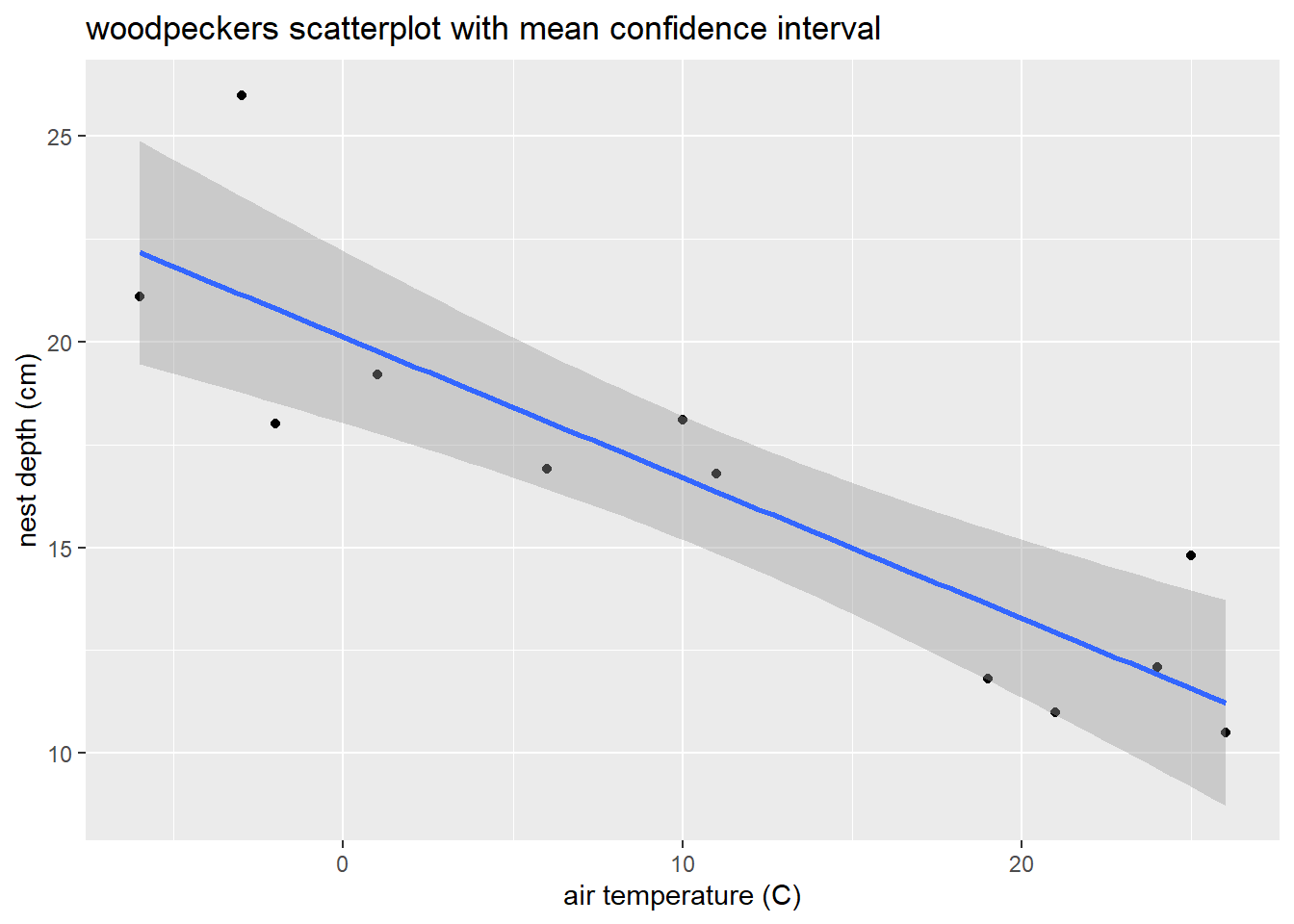
Adding prediction interval bands takes slightly more work. First, create a new version of the data set that includes prediction intervals for each case in the data:
## temp depth fit lwr upr
## 1 -6 21.1 22.17535 16.30939 28.04131
## 2 -3 26.0 21.14882 15.42438 26.87325
## 3 -2 18.0 20.80664 15.12396 26.48932
## 4 1 19.2 19.78011 14.20554 25.35468
## 5 6 16.9 18.06922 12.61459 23.52385
## 6 10 18.1 16.70051 11.28483 22.11620Then add a geom_ribbon layer to the previous plot, with ymin and ymax determined by the prediction interval’s lower (lwr) and upper (upr) bounds. The fill arguments in both layers below are not really needed, but they are used here to provide a legend label for the plot:
ggplot(wpdata_pred, aes(x = temp, y = depth)) + # global x/y variables for all geoms
geom_point() + # plot data
geom_ribbon( # add "ribbon" geom for bands
aes(ymin = lwr, # lower prediction bound at a given temp
ymax = upr, # upper prediction bound at a given temp
fill = "prediction"), # quick way to get a legend
alpha = .1) + # alpha closer to 0 makes ribbon more transparent
geom_smooth(method = "lm", # add confidence bands too with smooth geom
aes(fill = "confidence"), # another fill for confidence bands
alpha = .4) + # lower transparency
labs(x = "air temperature (C)", y = "nest depth (cm)",
title = "woodpeckers scatterplot",
fill = "Type") # fill legend title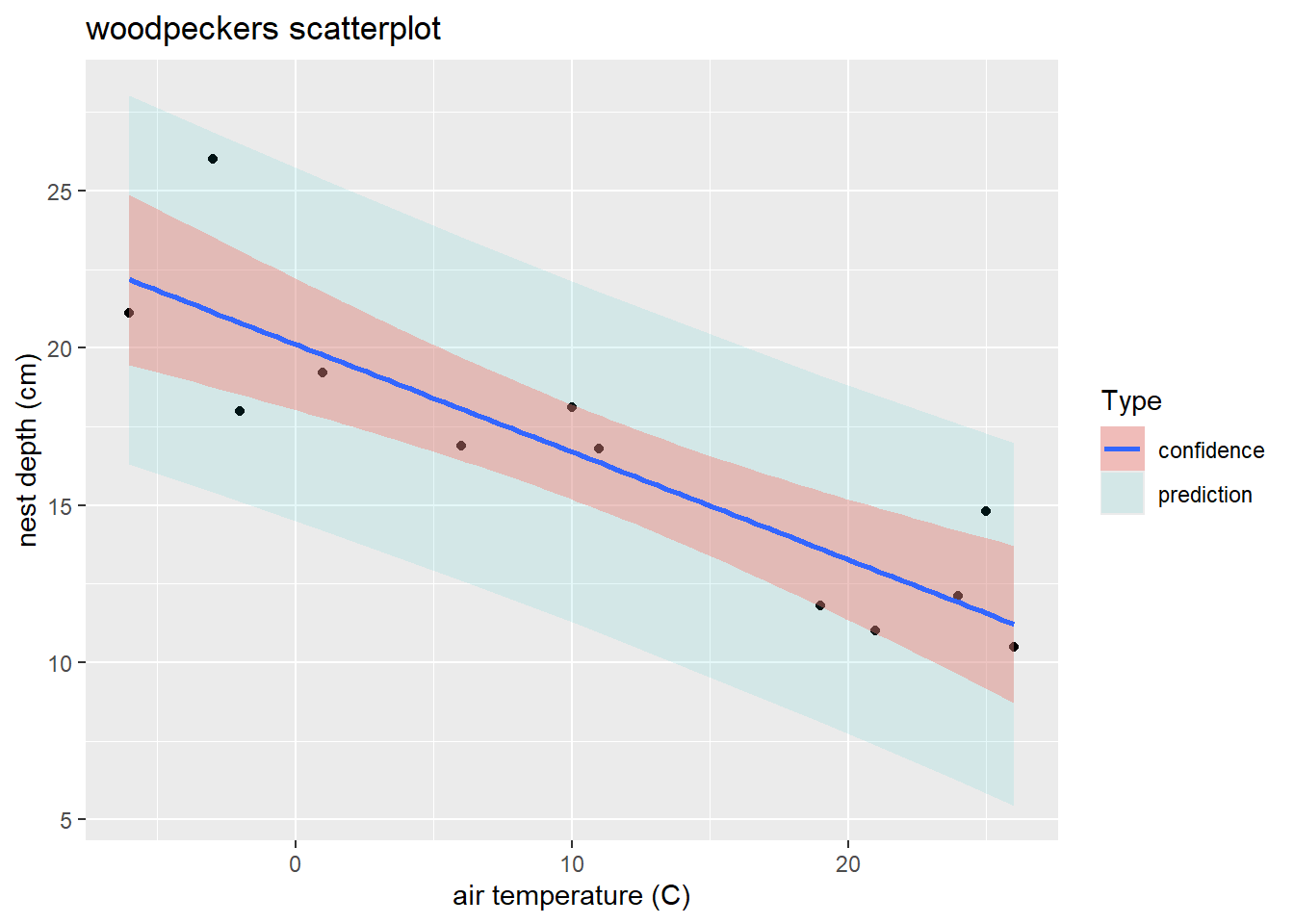
2.9 Checking model assumptions and fit
Recall the SLR model assumptions from 2.3:
\[ Y_i = \beta_0 + \beta_1 x_i + \epsilon_i \ \ \ \ \ \epsilon_i \sim N(0, \sigma) \]
- Linearity: The mean response varies linearly with \(x\).
- Constant SD: \(SD(Y\mid x)=\sigma\) describes the SD of \(Y\)’s in the population around a given mean value \(\mu_{y\mid x}\). An equivalent statement of this assumption is that the model errors should not be associated with \(x\).
- Normality: The shape of population response values around \(\mu_{y\mid x}\) is described by a normal distribution model.
- Indepedence: Given a predictor value of \(x\), all responses \(Y\) occur independently of each other. An equivalent statement of this assumption is that the model errors are independent.
2.9.1 Residuals
If all four model assumptions are met, then our model errors \(\epsilon_i\)’s will be independent and distributed like \(N(0,\sigma)\). Now we can’t actually “see” the model errors unless we know the true parameter values in the population since \[ \epsilon_i = y_i - (\beta_0 + \beta_1 x_i) \]
The closest thing we have to the model errors are the fitted model residuals computed using the estimated model parameters: \[ r_i = y_i - (\hat{\beta}_0 + \hat{\beta}_1 x_i) \] Residuals for a fitted model are a diagnostic tool to help check whether a model fit to data seems to match the true model form that generated the data.
2.9.2 Residual plot: linearity and constant variance
A residual plot is constructed by plotting \(r_i\) (y-axis) against \(x_i\) (x-axis). A horizontal reference line at \(y=0\) is usually added (since the mean residual value is always 0).
- Linearity: This assumption is met if, at each x-value, you see similar scatter of points (residuals) above and below the 0-reference line.
- Constant variance: This assumption is met if you see a similar magnitude of point scatter around the 0-reference line as you move along the x-axis.
A residual plot that meets both these conditions is called a null plot.
Watch out for
- curvature which suggests the mean function relating \(y\) and \(x\) may not be linear
- nonconstant variation which is seem in “fan” shaped plots
- outliers which can have a large influence on the fitted model
2.9.2.1 Example: Nest depth residual plot
Let’s revisit the woodpecker nesting depth model and use the broom package to add residuals to the wpdata data frame (Section 2.7.3.1):
# model fit above in Section 2.7 example
wpdata <- read.csv("https://math.carleton.edu/kstclair/data/woodpeckers.csv")
wood_lm <- lm(depth ~ temp, data = wpdata)
library(broom)
wpdata_aug <- augment(wood_lm)
head(wpdata_aug)## # A tibble: 6 × 8
## depth temp .fitted .resid .hat .sigma .cooksd .std.resid
## <dbl> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 21.1 -6 22.2 -1.08 0.272 2.42 0.0544 -0.540
## 2 26 -3 21.1 4.85 0.211 1.66 0.732 2.34
## 3 18 -2 20.8 -2.81 0.194 2.23 0.215 -1.34
## 4 19.2 1 19.8 -0.580 0.149 2.45 0.00632 -0.269
## 5 16.9 6 18.1 -1.17 0.0996 2.43 0.0154 -0.528
## 6 18.1 10 16.7 1.40 0.0840 2.41 0.0180 0.626The residual plot will put the predictor temp on the x-axis and .resid on the y-axis:
library(ggplot2)
ggplot(wpdata_aug, aes(x = temp, y = .resid)) +
geom_point() +
geom_hline(yintercept = 0, linetype = "dashed") +
labs(y = "residuals", title = "Residual plot")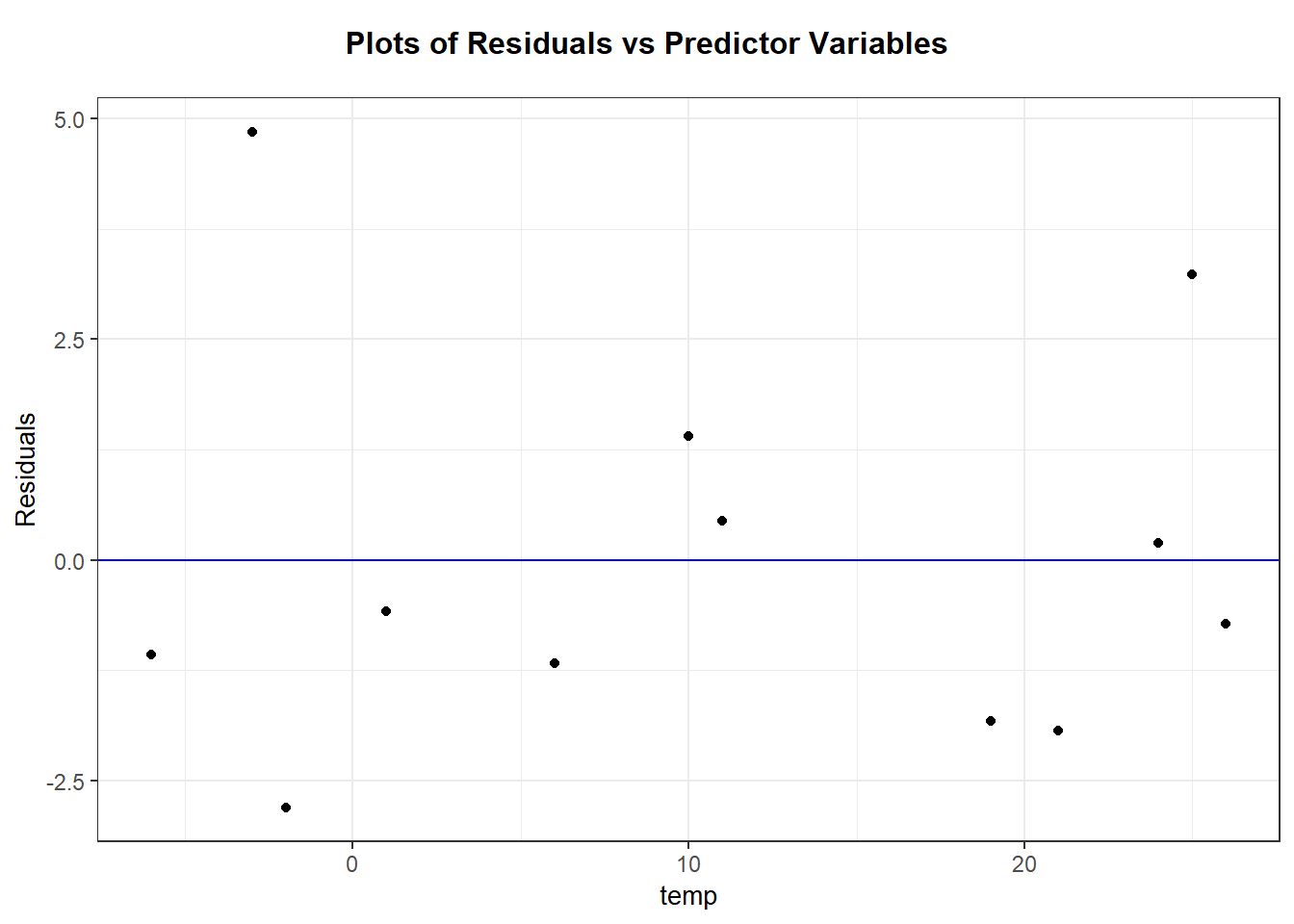
Don’t forget to use the augmented data frame wpdata_aug that contains the residuals. The layer geom_hline adds the horizontal reference line at 0.
Interpretation: There are no majors trends seen in this residual plot. Generally, it is hard to prove or disprove model assumptions when we only observe 12 data points!
2.9.2.2 Packages for regression diagnostics
There are plenty of R packages that help automate the creation of diagnostic plots like the residual plot. One package that we will use in this class is ggResidpanel. To quickly get the plot of residuals against the predictor, we can use the command resid_xpanel:
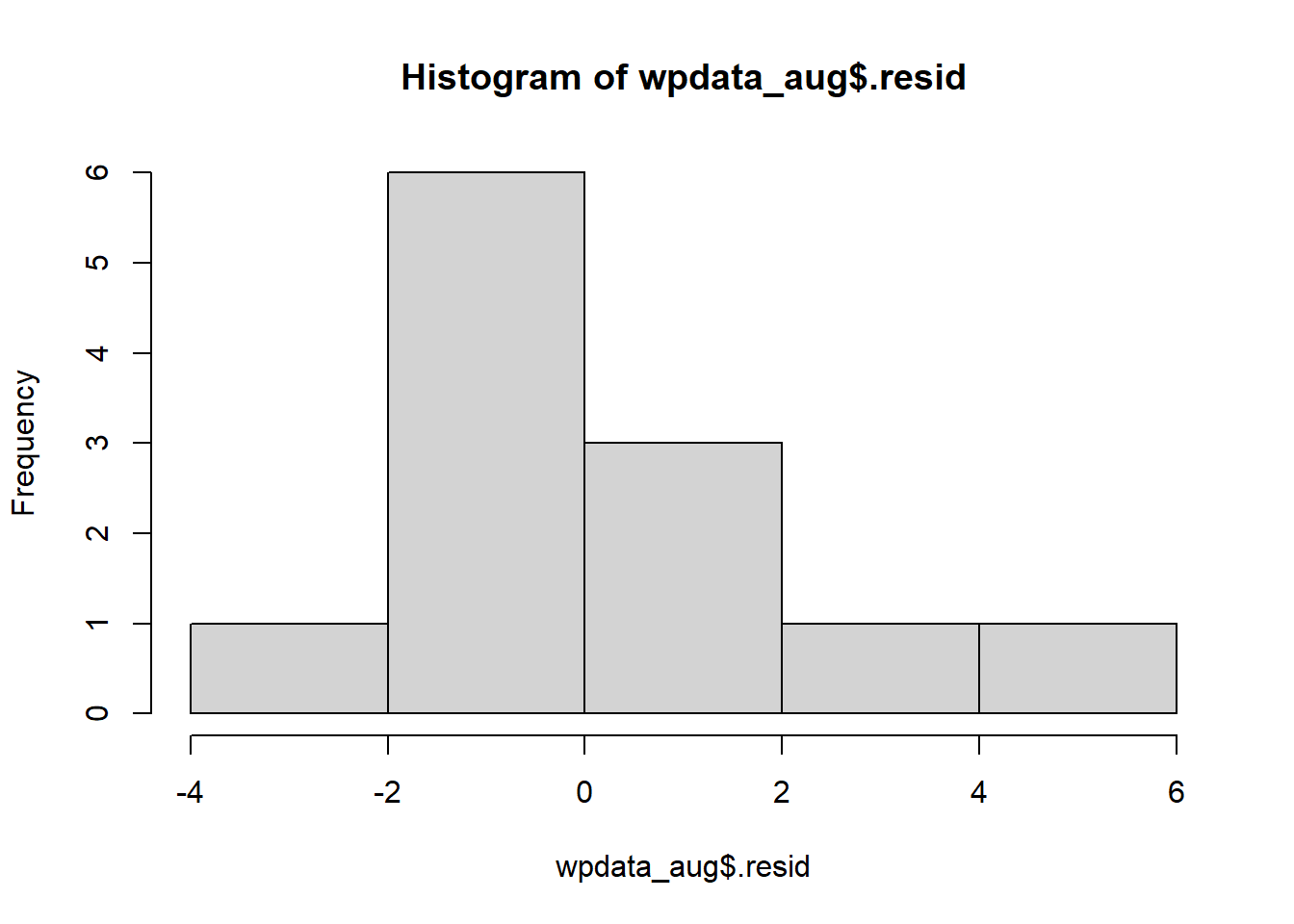
Make sure you are comfortable both creating diagnostic plots by hand and using the ggResidpanel package. The latter is good for quick and easy diagnostic plots, but knowing how to creat and customize plots by hand is also important for certain applications.
2.9.3 Residual normal QQ plot
A normal QQ plot for a variable plots observed quartiles against the theoretical quartiles from a normal model. If these points follow a line then the data is approximately normal. Here is a general guide for interpreting non-linear trends that indicate a non-normal distribution:
- Concave up: the distribution is right skewed
- Concave down: the distribution is left skewed
- S-shaped: the distribution is symmetric but the tails are either too short (not enough variation) or too long (too much variation) to be normally distributed.
- More help! Check out this website for a deeper discussion of the interpretation of normal QQ plots
We can check the normality assumption by plotting residuals with a normal QQ plot. You can also use a histogram of residuals to help interpret the normal QQ plot.
2.9.3.1 Example: Residual normal QQ plot
Back to the augmented woodpecker data set. A histogram of the residuals shows a slightly right skewed distribution.
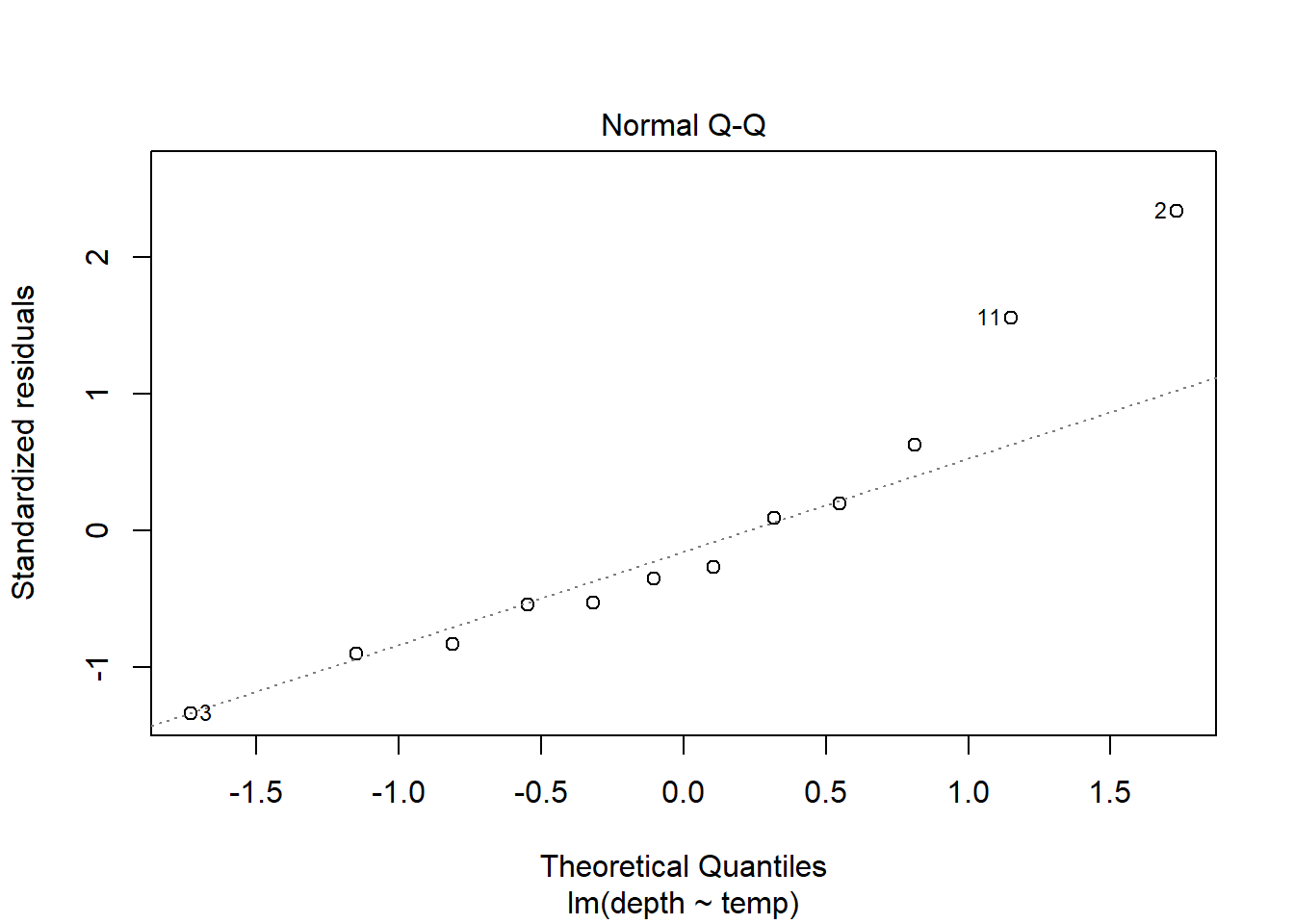
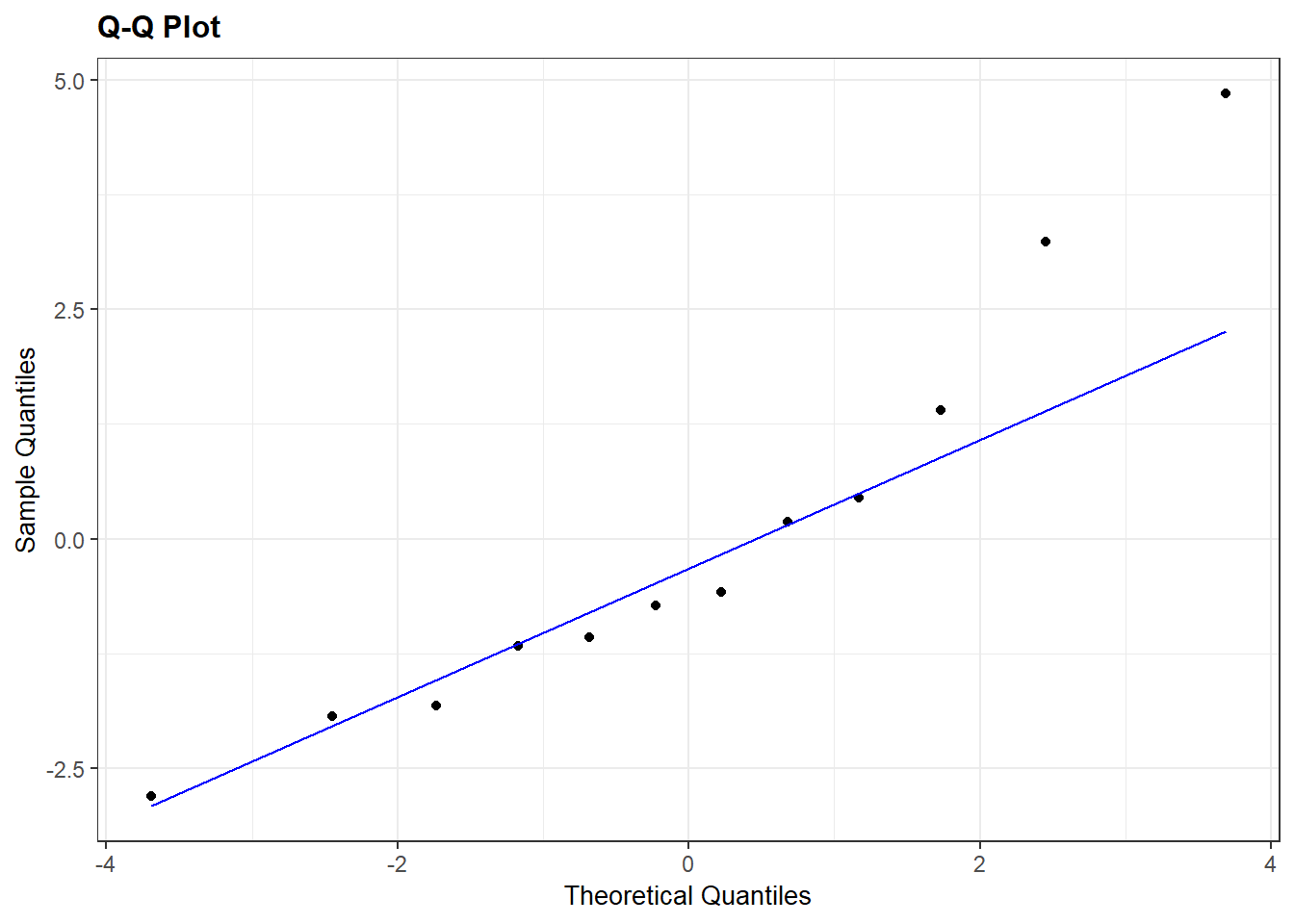
A quick way to get a normal QQ plot of residuals is to plug the lm object into the plot command and request plot number 2:
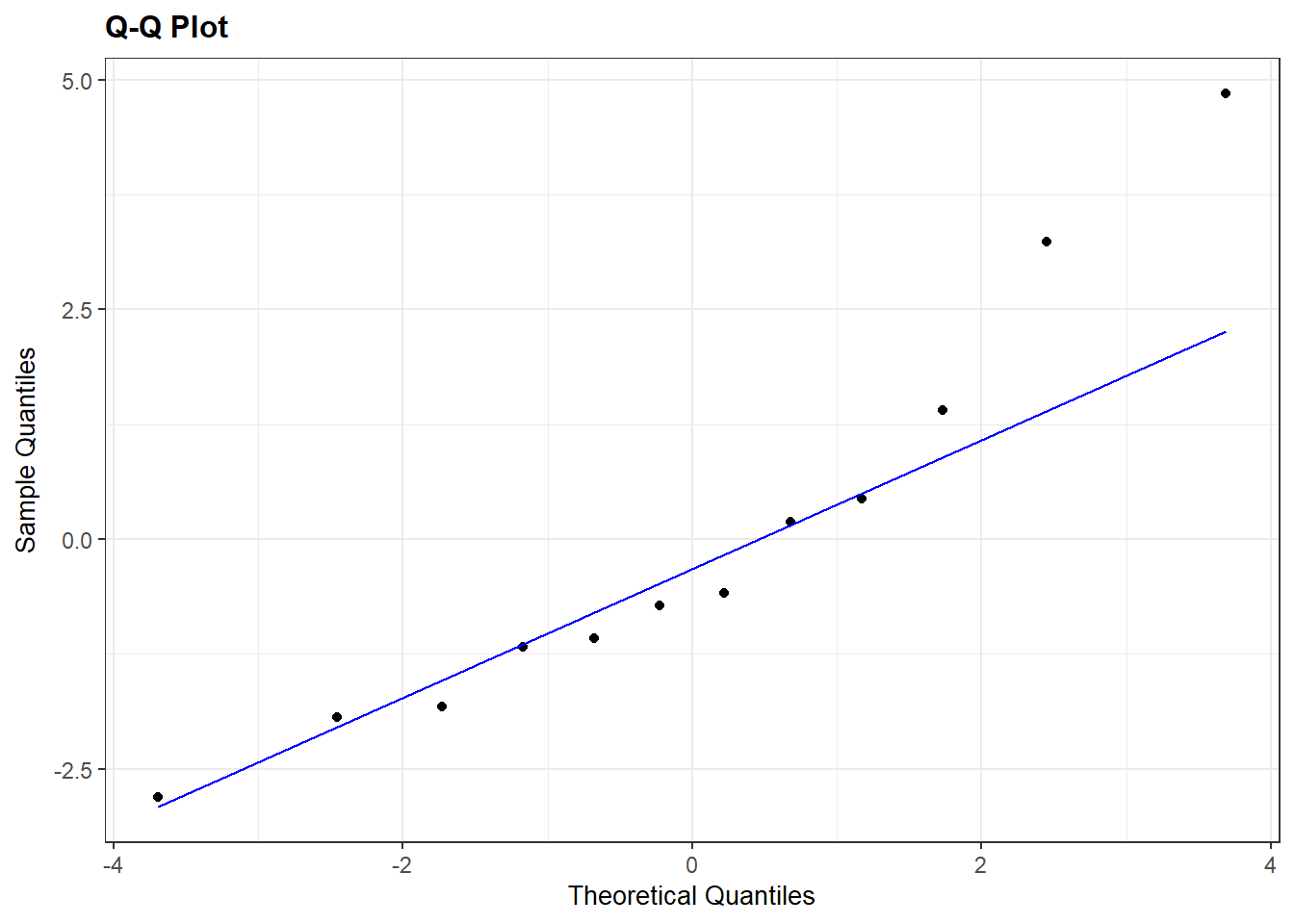
 Similarly, the package
Similarly, the package ggResidpanel can also create this plot with resid_panel:
 If you wanted to ID the “weird” points (here, the cases in the right tail), you can switch to the
If you wanted to ID the “weird” points (here, the cases in the right tail), you can switch to the resid_interact command which creates a plotly graph that will interactively show data for points that you hover over:
Alternatively, you could use a ggplot. The aesthetic used for a QQ plot in a ggplot is sample = variable, then geom_qq and geom_qq_line are the layers used:
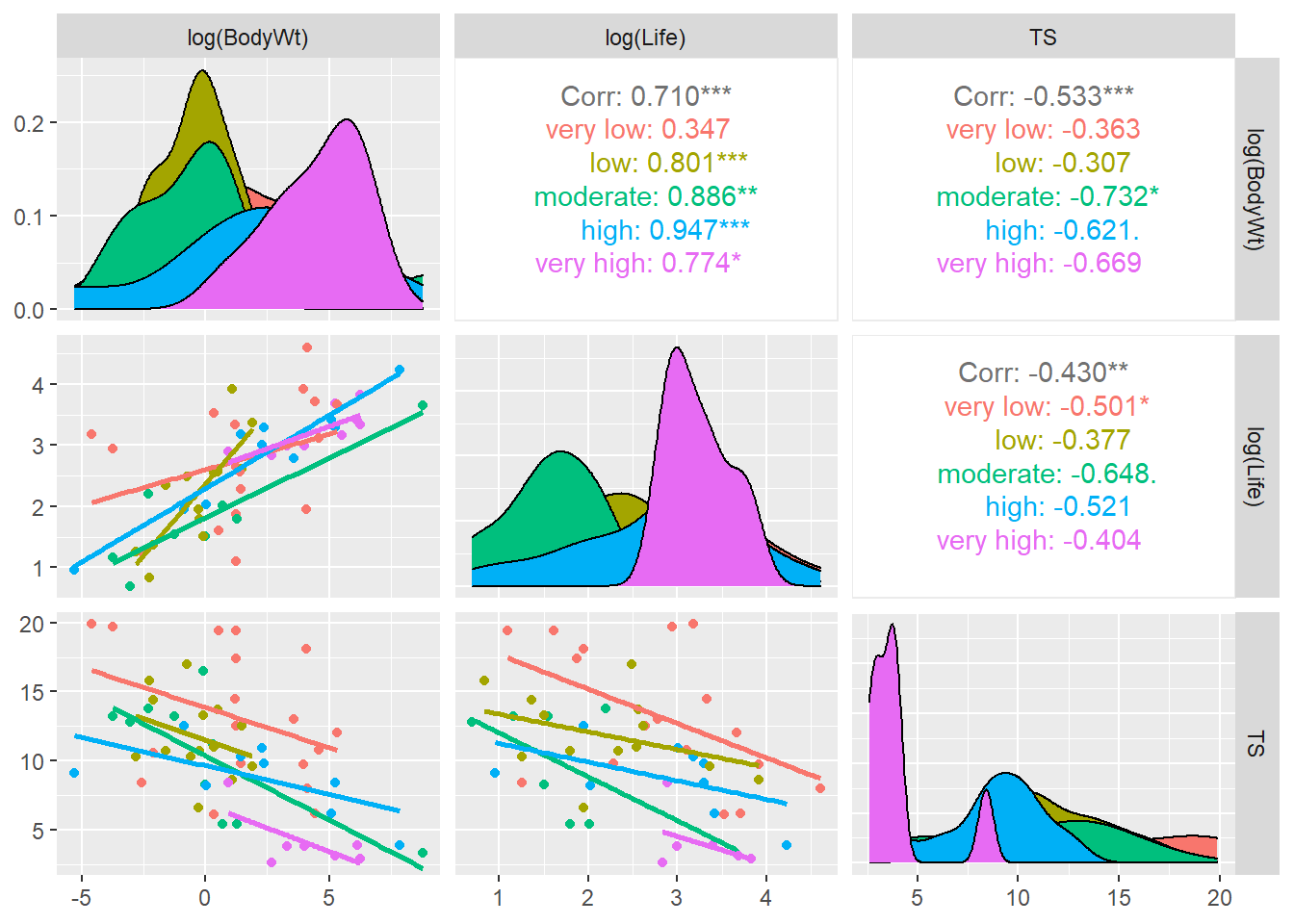
Interpretation: The QQ plot also suggests a slightly longer right tail because it is (sort of) concave up. But, the QQ plot also clearly shows that this feature could just be due to two cases with residual values that are slightly higher than all others. Again, because there are only 12 data points these two cases could just be due to chance and we can conclude that there aren’t any strong indications of a non-normal distribution.
2.9.4 Independence
Independence of errors is probably the hardest assumption to check because it often depends on how the data was collected. Two common scenarios that lead to data that violates this assumption are
- temporal correlation: This means correlation of errors because measurements were collected over time. Responses (and errors) measured close in time are more likely to be similar in value that responses measured further apart in time. For example, daily temperature readings in Northfield are temporally correlated.
- spatial correlation: This means correlation of errors because measurements were collected over a spatial region Responses (and errors) measured close together in space are more likely to be similar in value that responses measured further apart in space. For example, home values a sample of houses in St. Paul are likely spatially correlated since the value of a house is likely more similar to it’s neighbor than to a house across town.
One method of checking for these two types of dependence is to plot the model residuals \(r_i\) (y-axis) against a variable that measures, or is associated, with time or space. For the time example, plot residuals against day of the year. For the spatial example, plot residuals against a categorical “neighborhood” variable.
2.9.5 Robustness against violations
Robustness of a statistical method means the conclusions we make using the method aren’t all that senstive to assumptions used to construct the method. Can we trust our SLR model inferences if a model assumption is violated?
Inference about \(\beta_0\), \(\beta_1\), and \(\mu_{y \mid x}\) from a SLR model are only robust against violations of the normality assumption. If \(n\) is large enough, then the Central Limit Theorem tells us that t-tests and t-CIs are still accurate.
SLR modeling is not robust against any other violations:
- Linearity: If your fitted mean model doesn’t match the form of the true mean then you will get incorrect inferences about predictor effects, mean responses, predicted responses, etc. Even your estimated model SD will be wrong!
- Constant variance and independence: If violated, the SE’s produced by the SLR model fit will not accuractely reflect the true uncertainty in our estimated parameters or predictions.
- Normality for prediction If the normality assumption is violated, then our prediction intervals will not capture the value of a new response “95% of the time”. (There is no CLT and “large n” to help us here when we are trying to predict one response!)
2.9.6 “Fixes” to violations
Here are some suggestions if a particular assumption is violated. The first part to consider “fixing” is linearity. If the mean function is not correctly specified then that will likely cause the other assumptions to not hold.
- Linearity: transform one or both variables to a different scale (e.g. logarithm, square root, reciprocal), modify the mean function (e.g. add a quadratic term), try non-linear regression
- Constant variance: tranform the response variable, weighted regression
- Normality: transform the response variable
- Independence: add more predictors, use a model with correlated errors (e.g. mixed effects, time series, spatial, etc)
2.10 Example: SLR assumptions
2.10.1 Drug offender sentences
The data set DrugOffenses2.csv contains data on 24,011 individuals convicted on federal drug charges during 2013 and 2014. We will subset these individuals to look only at cases given non-life prison sentences (sentence2 > 0), then look at the SLR of an individual’s sentence length (sent.nonlife) in months against their crimal history points (CRIMPTS).
2.10.1.1 Basic EDA shows that both sentencing and points variables are right skewed, and there are non-responses in each variable.
## [1] 24011 55library(dplyr)
drugPrison <- filter(drug, sentence2 > 0)
par(mfrow=c(1,2))
hist(drugPrison$CRIMPTS, main = "criminal points")
hist(drugPrison$sent.nolife, main = "sentence")
## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 0.00 0.00 2.00 3.51 5.00 42.00 2012## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 0.03 21.00 48.00 65.41 87.00 960.00 452.10.1.2 Usual scatterplot
The usual scatterplot suffers from overplotting when we have a large data sets or datasets with very discrete variables. It is hard to see where the majority of cases are in this plot and difficult to discern any trend in the response as we change the predictor variable.
library(ggplot2)
ggplot(drugPrison, aes(x = CRIMPTS, y = sent.nolife)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE)
2.10.1.3 Jittering and a loess smoother
Two ways to minimize the effect of overplotting are to
- “jitter” the plotted points by adding a small amount of random noise. This can be done by using
geom_jitterinstead ofgeom_point - use a more transparent plotting symbol. Then when points are overlapping, we will see darker colors which indicate a higher density of observations in that region of the graph. We do this by adding
alpha=to thegeom_jitterand make thealphavalue less than 1 (smaller values mean more transparent points).
We will also use a loess smoother line to the scatterplot to help reveal the true trend in sentencing as the point history changes. A smoother is a non-parameteric way to locally “average” the response as we change the predictor value. (Non-parametric means this isn’t a parameterized curve like a line or quadratic function, which means we don’t end up with a nice formula for \(y\) given \(x\) from such a model.) We fit the loess model to our plot by adding another layer of geom_smooth(method = "loess", se=FALSE). In the commands below, the aes(color=) just adds a color legend to the plot.
ggplot(drugPrison, aes(x=CRIMPTS, y=sent.nolife)) +
geom_jitter(alpha = .2) +
geom_smooth(method= "lm", se=FALSE, aes(color="lm")) +
geom_smooth(method="loess", se=FALSE, aes(color="smoother"))
2.10.1.4 Hex plots
Hex plots are another alternative to a basic scatterplot when you have a lot of data. The basic idea is that cases with similar x/y values are grouped into the same “hex bin” (similar is defined by a hexagon shape on the x-y plane), then the number of cases in this bin is recorded and this count is shown as a color aesthetic in the graph. The geom_hex geometry can create this plot in the ggplot2 environment:
ggplot(drugPrison, aes(x=CRIMPTS, y=sent.nolife)) +
geom_hex() +
geom_smooth(method= "lm", se=FALSE, aes(color="lm")) +
geom_smooth(method="loess", se=FALSE, aes(color="smoother")) +
labs(color = "type")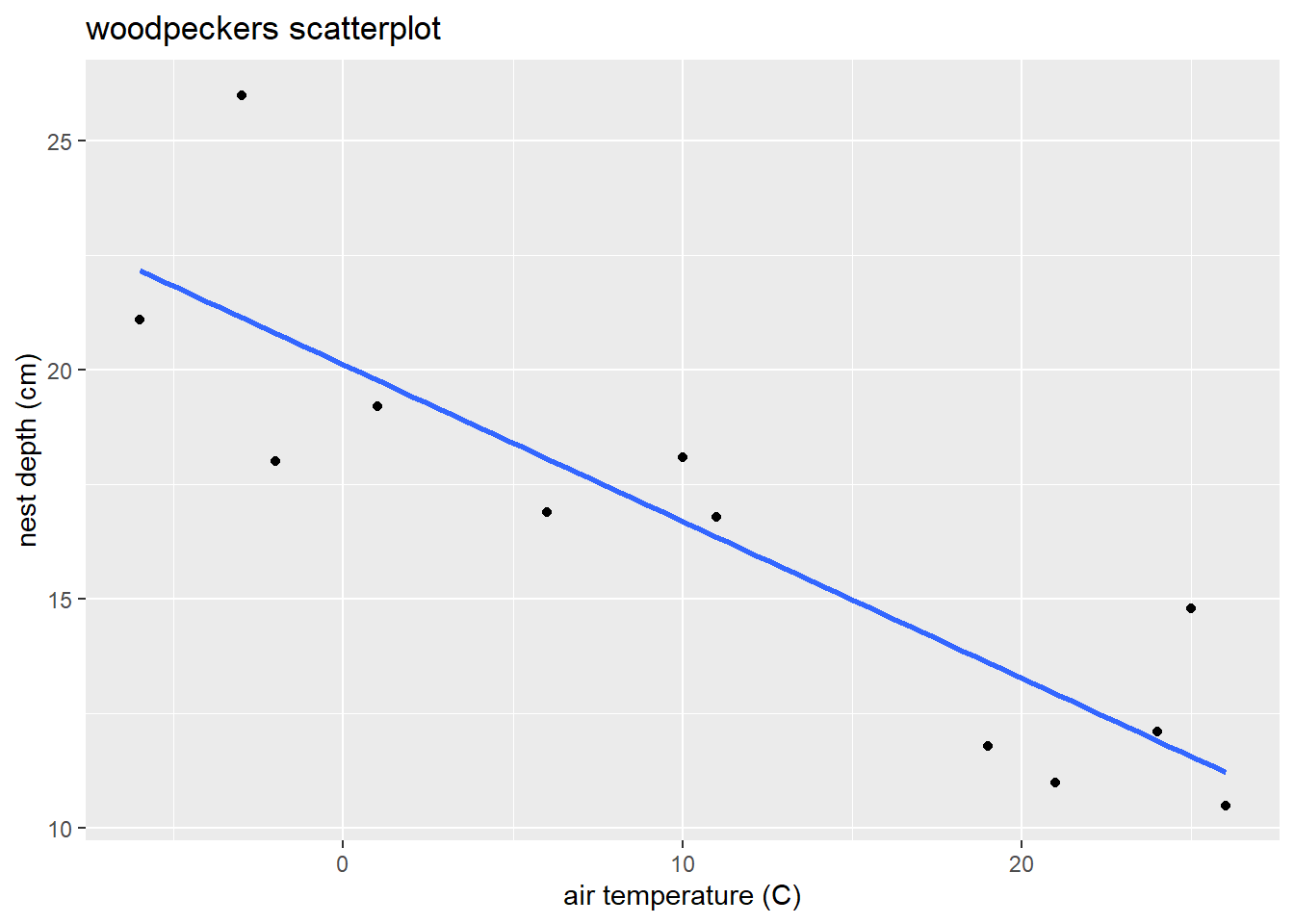
Here we see that the highest case counts occur for the lowest combinations of crime history score and sentence length.
2.10.1.5 Residual plot and loess smoother
The scatterplot and loess smoother suggest there is slight quadratic relationship between points history and sentence length, with a positive trend up to about 20 points and a negative trend after. We can see this too in the residual plot with loess smoother added. The variation around the regression line seems fairly similar for any points value up to about 20 points, and after 20 points there are fewer cases which seem to be slightly less variable. (Note that “similar variation” means the spread around the line is of similar magnitude for any value of x, not that the spread around the line is symmetric. As we see next, the spread around the line (residuals) is skewed right.)
drug_lm <- lm(sent.nolife ~ CRIMPTS, data=drugPrison)
library(broom)
drugPrison_aug <- augment(drug_lm)
ggplot(drugPrison_aug, aes(x=CRIMPTS, y=.resid)) +
geom_jitter(alpha = .2) +
geom_smooth(method= "lm", se=FALSE, aes(color="lm")) +
geom_smooth(method="loess", se=FALSE, aes(color="smoother"))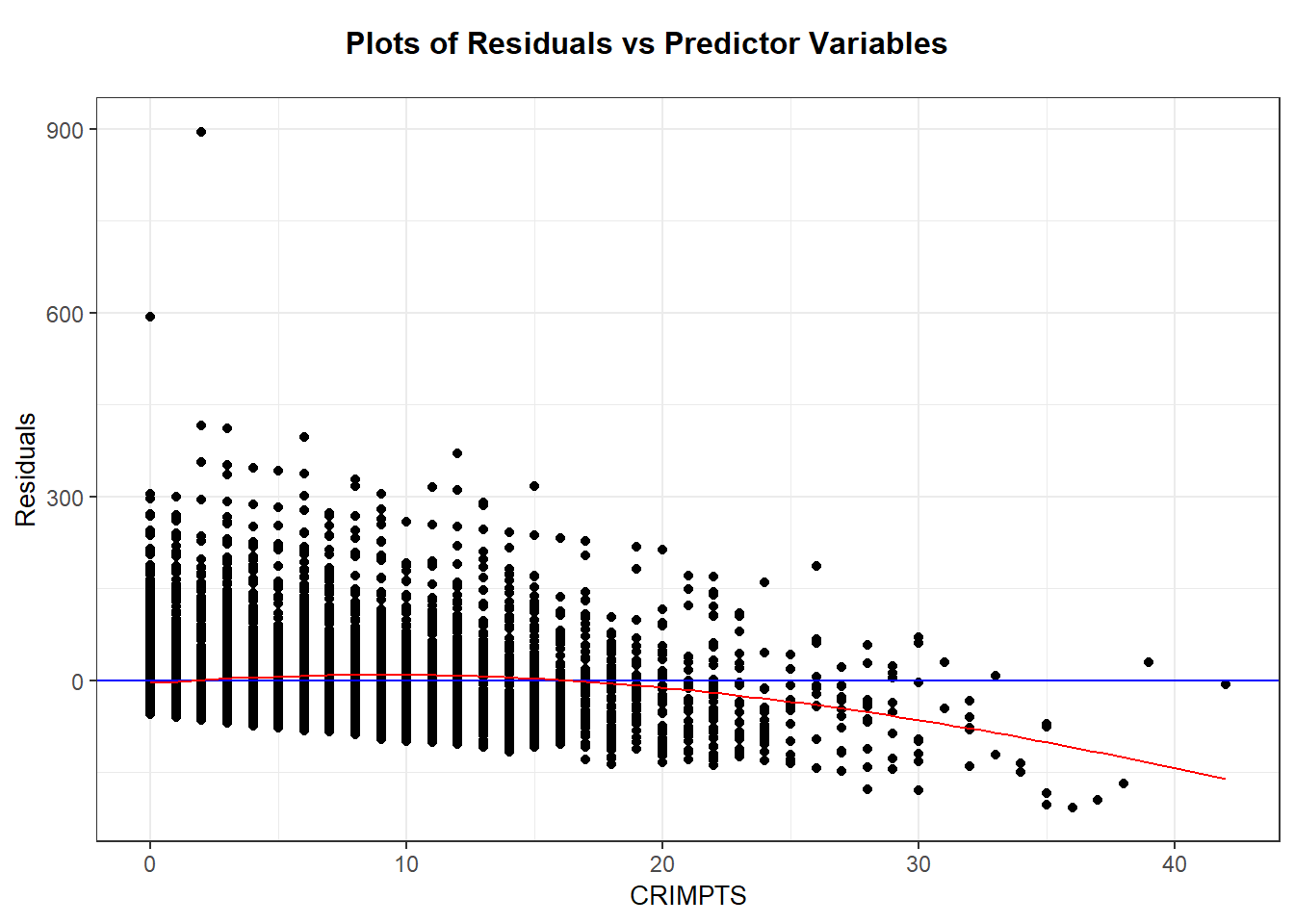
We can create a non-jittered version of this residual plot by adding a smoother argument to resid_xpanel:
2.10.1.6 Checking normality
The residuals for this model are not normally distributed, there is a strong skew to the right. If the linear model fit the trend of the data, this non-normality would not be a concern for inference about the mean parameters \(\beta\). It would only be a concern if we wanted to predict one individual’s sentence length with confidence given their criminal history points.
2.10.2 Case study 15.2 - Global Warming
Let’s look at the regression of global mean temperature deviation (Celsius) on year (1850 through 2010). The scatterplot suggests a curved relationship with time. Temperature deviation is the mean yearly temp minus the mean temp from all 161 years.
## Year Temperature
## Min. :1850 Min. :-0.6060
## 1st Qu.:1890 1st Qu.:-0.3000
## Median :1930 Median :-0.1740
## Mean :1930 Mean :-0.1153
## 3rd Qu.:1970 3rd Qu.: 0.0260
## Max. :2010 Max. : 0.6200ggplot(temps, aes(x = Year, y = Temperature)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE) +
geom_smooth(method = "loess", se = FALSE, linetype = "dashed")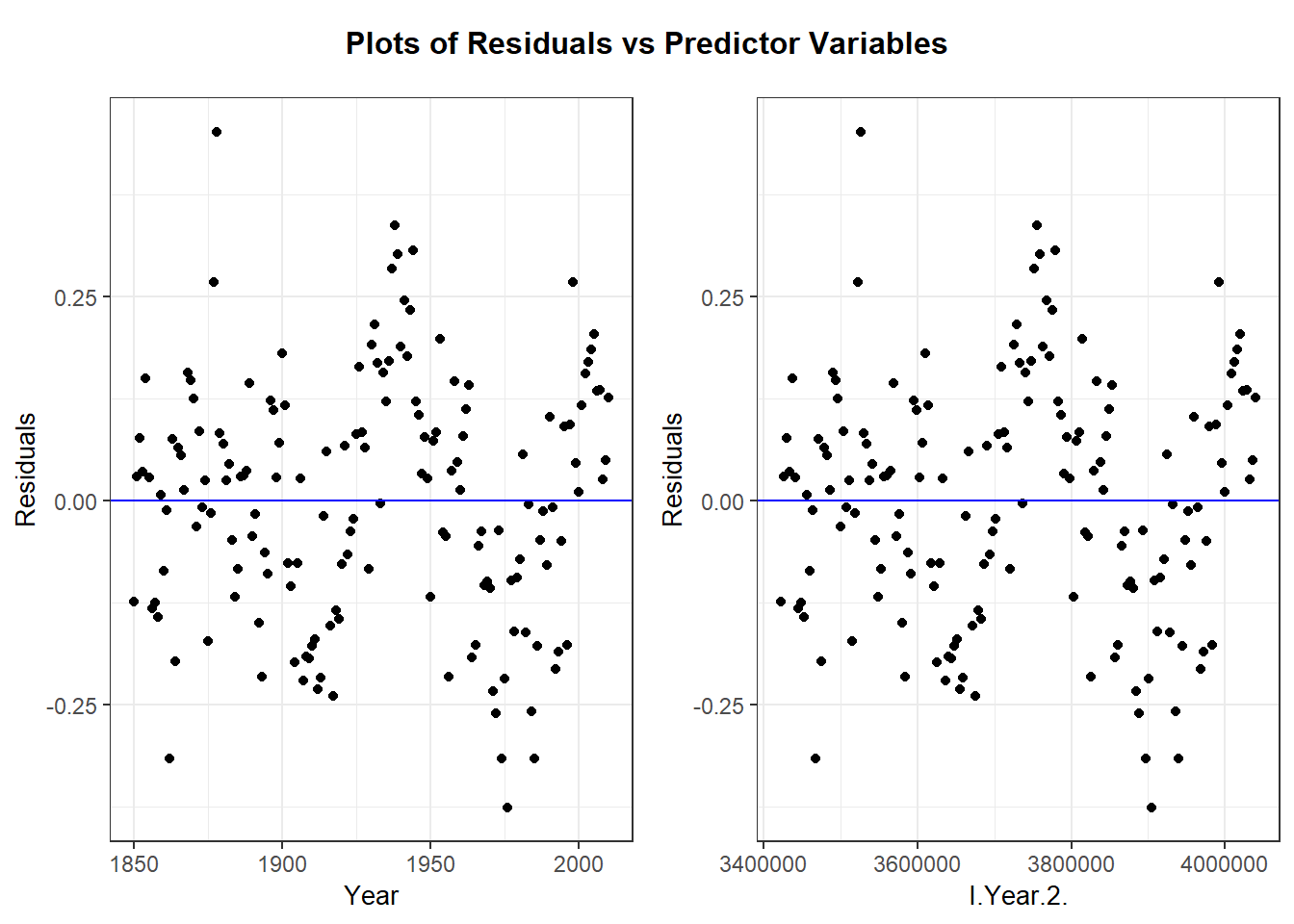
2.10.2.1 Independent residuals?
After fitting our regression of Temperature on Year and Year^2 (due to curvature), a check of the residual plot (residuals vs. Year) shows an improvement in the model that only includes Year (and omits the quadratic term).
temps_lm <- lm(Temperature ~ Year + I(Year^2), data=temps)
temps_aug <- augment(temps_lm)
head(temps_aug)## # A tibble: 6 × 9
## Temperature Year `I(Year^2)` .fitted .resid .hat .sigma .cooksd .std.resid
## <dbl> <int> <I<dbl>> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 -0.371 1850 3422500 -0.247 -0.124 0.0545 0.150 1.39e-2 -0.850
## 2 -0.222 1851 3426201 -0.251 0.0289 0.0519 0.151 7.13e-4 0.198
## 3 -0.178 1852 3429904 -0.255 0.0770 0.0493 0.151 4.78e-3 0.526
## 4 -0.224 1853 3433609 -0.259 0.0350 0.0469 0.151 9.31e-4 0.238
## 5 -0.113 1854 3437316 -0.263 0.150 0.0446 0.150 1.62e-2 1.02
## 6 -0.238 1855 3441025 -0.267 0.0285 0.0424 0.151 5.55e-4 0.194ggplot(temps_aug, aes(x = Year, y = .resid)) +
geom_point() +
geom_hline(yintercept = 0, linetype = "dashed")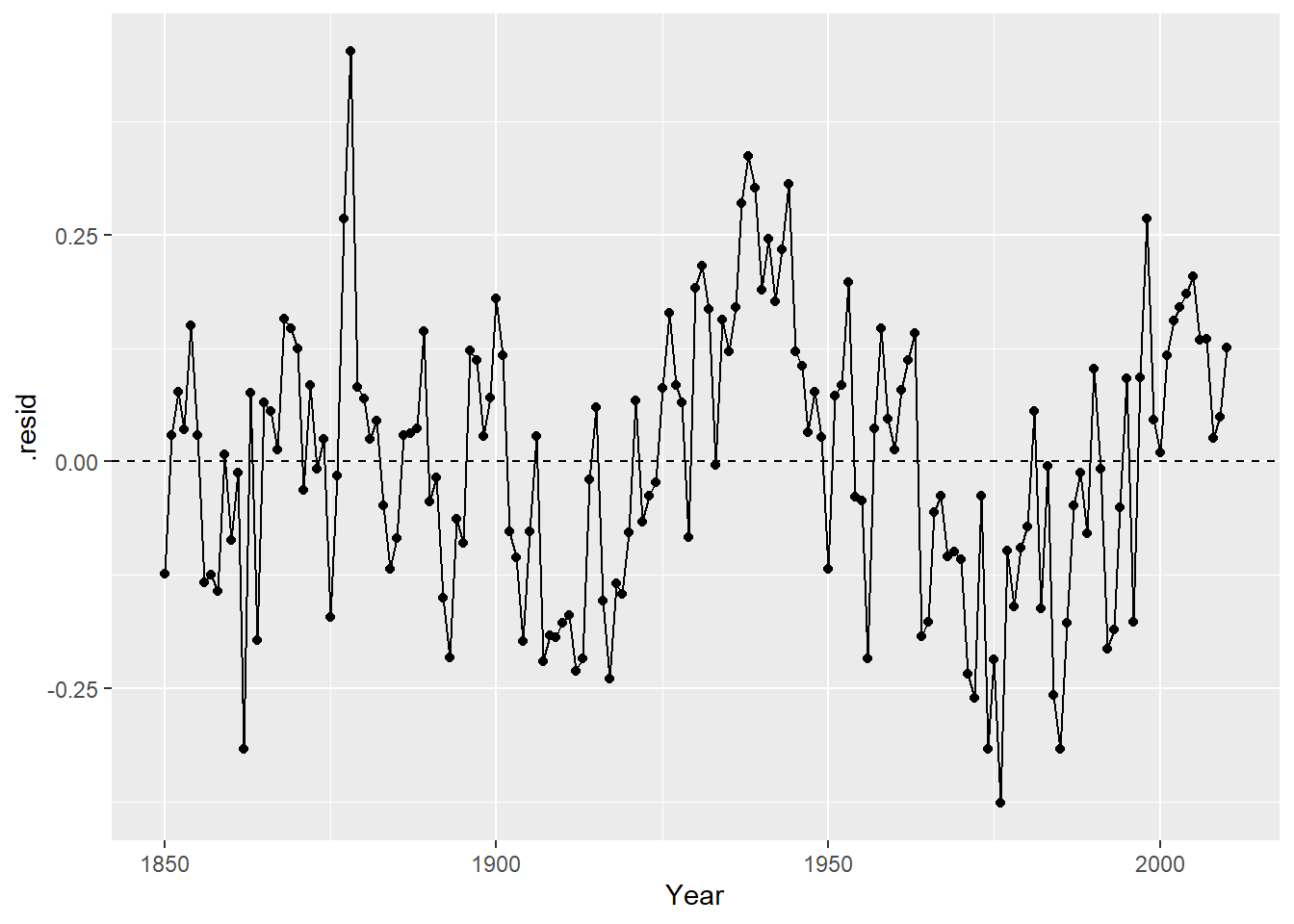
The independence assumption will be violated for this model if residuals closer in time (x) are more similar than residuals further apart in time. This is hard to see in the basic residual plot above. To see this idea better, we can look at line plot of residuals vs. time:
ggplot(temps_aug, aes(x = Year, y = .resid)) +
geom_point() +
geom_line() +
geom_hline(yintercept = 0, linetype = "dashed")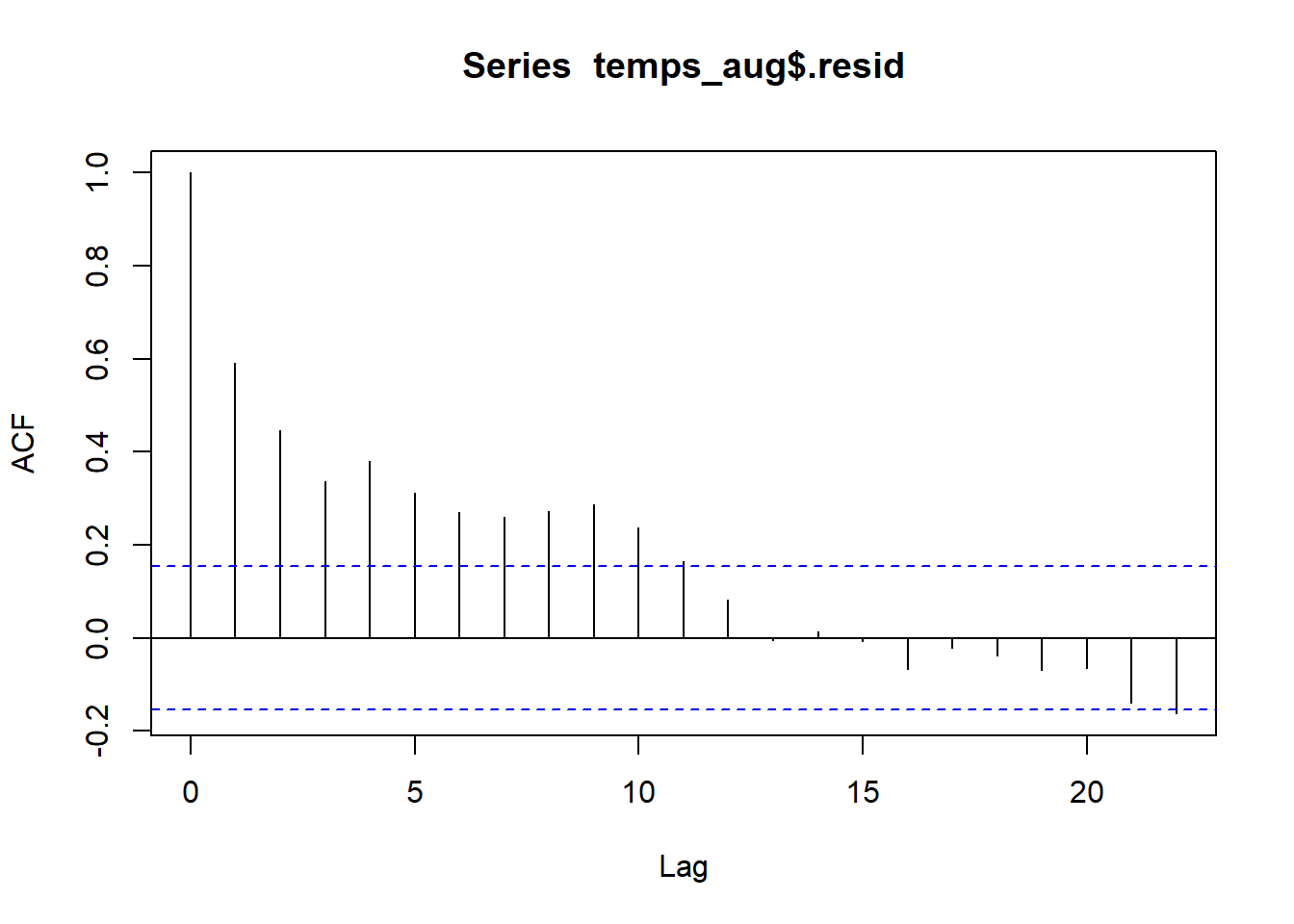
With this plot is it clear that if one year has a negative residual (lower than expected temps), the next year’s residual is often also negative. Same is true for positive residuals. This indicates that there is a temporal association in these residuals, which means that they are not independent. A SLR model is not appropriate for this data because the SEs will not accurately reflect the uncertainty in our estimates when independence is violated.
2.10.2.2 Autocorrelation
The correlation statistic is used to assess the strength and direction of a linear relationship between two quantitative variables. The autocorrelation is used to assess how correlated values are for the same quantitative variable. Autocorrelation is computed by pairing responses by a lag amount. Lag of 1 means we are computing correlation for responses that differ by one spot in the vector of responses. For our time and temp data, this means looking at the correlation between responses that differ by a year. Lag 2 means looking at correlation between responses that differ by 2 years, and so on.
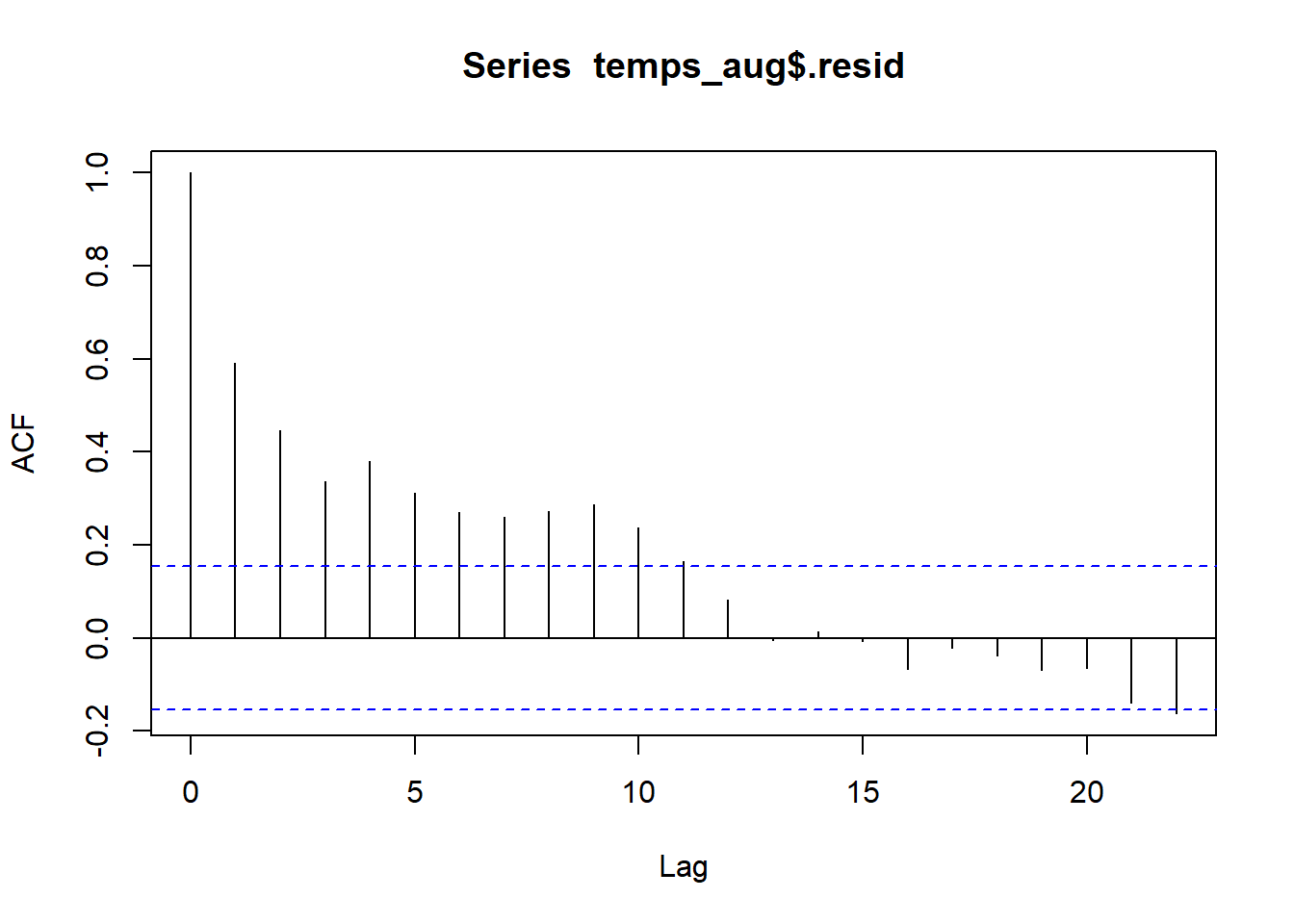
We can use autocorrelation to verify that residuals closer together in time are more similar than those further apart in time:
##
## Autocorrelations of series 'temps_aug$.resid', by lag
##
## 0 1 2 3 4 5 6 7 8 9 10
## 1.000 0.592 0.446 0.336 0.380 0.313 0.270 0.261 0.272 0.287 0.236
## 11 12 13 14 15 16 17 18 19 20 21
## 0.164 0.083 -0.004 0.014 -0.007 -0.067 -0.022 -0.038 -0.069 -0.065 -0.140
## 22
## -0.162Residuals that differ by one year have a correlation of 0.592, indicating a moderate positive correlation. This is what were able to see in the line plot above. Residuals that differ from 2-9 years have correlations between about 0.45 to 0.25. After years there is little to no autocorrelation between residuals.
2.11 Transformations
Transformations of one or both variables in SLR is done to fix one, or both, of these assumption violations: linearity and constant variance. Tranformations are often explored via trial-and-error, use plots of transformed variables and residual plots from potential transformed SLR models to find the “best” SLR model. “Best” is determined by a model that most satisfies the SLR assumptions, not a model that yields the “strongest” relationship between variables. A transformation choice can also be determined from a theoretical model that we have from a specific application.
2.11.1 Transformation choices
We need to look at non-linear functions of a variable. A linear transformation, like changing a measure from cm to feet would only change the numbers you see on the axes label and not the relative location of points on the plot. Common transformations to consider are the following:
- logarithms: Any log-base can be explored but base choice will only affect how you interpret a model, not affect the linearity or constant variance assumptions. E.g. if \(\log_2(y)\) vs. \(x\) looks nonlinear, then \(\log_{10}(y)\) vs. \(x\) will also be nonlinear. Logarithms are nice because they are easily interpretable in a SLR model (more to come). In R,
## [1] 0.6931472## [1] 0.30103## [1] 1- square root: A square root transformation is an “in between” no transformation and a logarithm transformation (see the Figure below)
## [1] 2
2.11.2 Transformations in R
We can visualize square root and logarithms in aggplot2 scatterplot by adding a layer that changes the scale of an axes. For example, scale_x_sqrt() will change the geom_point() scatterplot to a plot of \(y\) aganist \(\sqrt{x}\) but the axes numeric labels on the x-axis will still measure \(x\). The layer scale_y_log10() will convert \(y\) to the base-10 logarithm. If you want a transformation that is not one of these two, then you can transform the variable in the aesthetic: ggplot(data, aes(x = 1/x, y = y)) would plot \(y\) against the reciprocal \(1/x\).
You can apply transformations directly in the lm command too, e.g. lm(log(y) ~ log(x), data) fits the regression of \(\log(y)\) against \(\log(x)\). If a transformation involves a mathematics function (like power ^ or division /) on the right side of the formula symbol ~, then you need to use the “as is” operator function I(). E.g. the regression of \(y\) against the reciprocal \(1/x\) is lm(y ~ I(1/x), data).
2.11.3 Interpretation
In general, models with transformed variables should be interpreted as a usual SLR but with the transformed variable scale. For example, the SLR for \(\sqrt{y}\) against \(\sqrt{x}\) has a mean function that looks like \[ \mu_{\sqrt{y} \mid x} = \beta_0 + \beta_1 \sqrt{x} \] so a one unit increase in the square root of \(x\) in associated with a \(\beta_1\) change in the mean of the square root of \(y\).
Models that use logarithms have a nicer interpretation. Section 2.11.4 has more review of logarithms but the three common SLR models that use logarithms are given here.
- Logarithmic model: The regression of \(Y\) on \(\log(x)\) has the mean function \[ \mu(Y \mid \log(x)) = \beta_0 + \beta_1 \log(x) \] Multiplying \(x\) by a factor \(m\) is associated with a mean function change of \[ \mu(Y \mid \log(mx)) - \mu(Y \mid \log(x)) = \beta_1(\log(m) + \log(x)) - \beta_1 \log(x) = \beta_1 \log(m) \] If base-2 is used for the tranformation of \(x\) then a doubling of \(x\) (so \(m=2\)) is associated with a change in mean \(y\) of \(\beta_1 \log_2(2) = \beta_1\).
- Exponential model: The regression of \(\log(Y)\) on \(x\) has the mean function
\[
\mu(\log(Y) \mid x) = median(\log(Y) \mid x) = \beta_0 + \beta_1 x
\]
Since the median of a logged-variable equals the log of the median of the variable, we can “untransform” this model and write it in terms of the median of \(Y\) (assuming here that
logis the natural log): \[ median(Y \mid x) = e^{\log(median(Y \mid x))} = e^{median(\log(Y) \mid x)} = e^{\beta_0}e^{\beta_1 x} \] Note that the mean of a logged-variable does not equal the log of the mean of the variable, so we can’t express the untransformed model in terms of the median of \(Y\).
A one unit increase in \(x\) is associated with a \(e^{\beta_1}\)-factor change in the median function since \[ median(Y \mid x+1) = e^{\beta_0}e^{\beta_1 (x+1)} = e^{\beta_0}e^{\beta_1 x}e^{\beta_1} = median(Y \mid x) e^{\beta_1} \] - - Power model: The regression of \(\log(Y)\) on \(\log(x)\) has the mean function \[ \mu(\log(Y) \mid \log(x)) = median(\log(Y) \mid\log(x)) = \beta_0 + \beta_1 \log(x) \] Using the same logic as the exponential model, inference on the untransformed scale of \(Y\) is about the median of \(Y\): \[ median(Y \mid x) = e^{\log(median(Y \mid x))} = e^{median(\log(Y) \mid x)} = e^{\beta_0}e^{\beta_1 \log(x)} = e^{\beta_0}(e^{\log(x)})^{\beta_1} = e^{\beta_0}x^{\beta_1} \]
An m-fold (multiplicative) change in \(x\) is associated with a \(m^{\beta_1}\)-factor change in the median function since \[ median(Y \mid mx) = e^{\beta_0}e^{\beta_1 \log(mx)} = e^{\beta_0}(e^{\log(x)})^{\beta_1}(e^{\log(m)})^{\beta_1} = median(Y \mid x) m^{\beta_1} \]
I strongly suggest reviewing Section 2.11.4 below if you need a review of working with logarithms. Pay particular attention to Practice Problems 4-6 since they directly relate to these SLR models!
2.11.4 Review: Logarithms
Let \(b>0\) and \(x>0\). The logarithm (base-\(b\)) of \(x\) is denoted \(\log_b(x)\) and equal to \[ \log_b(x) = a \] where \(a\) tells us what power we must raise \(b\) to to obtain the value \(x\): \[ b^a = x \]
Easy examples are: \(b=2\), \(x=8\) and \(a=3\), \[ \log_2(8) = 3 \] since \(2^3 = 8\). Or using base \(b=10\), then \[ \log_{10}(0.01) = -2 \] since \(10^{-2} = 0.01\).
Some basic facts logarithm facts are \[ \log_b(b) = 1 \] since \(b^1 = b\) and \[ \log_b(1) = 0 \] since \(b^0 = 1\).
2.11.4.1 Changing a logged variable
Multiplicative changes in \(x\) result in additive changes in \(\log_b(x)\). If \(m>0\), then \[ \log_b(mx) = \log_b(m) + \log_b(x) \] For example, \[ \log_2(16) = \log_2(2\times 8) = \log_2(2) + \log_2(8) = 1 + 3 = 4 \]
2.11.4.2 Inverse (i.e. reversing the log, getting rid of the log, …)
The logarithm and exponential functions are inverses of one another. This means we can “get rid” of the log by calculating \(b\) raised to the logged-function: \[ b^{\log_b(x)} = x \] This will be useful in regression when we have a linear relationship between logged-response \(y\) and a set of predictors. We need to
For example, suppose we know that \[ \log_2(y) = 3 + 5x \] To return this to an expression on the original (unlogged) scale of \(y\), we need take both sides raised to the base 2: \[ 2^{\log_2(y)} = 2^{3 + 5x} \] Simplifying both sides gives \[ y = 2^3 \times 2^{5x} \]
2.11.4.3 Logarithm Practice Questions
Solutions are posted on the class Moodle site!
Write the following as the sum of two logarithms. Simplify as much as possible:
- \(\log_2(2x)\)
- \(\log_2(0.5x)\)
- \(\ln(2x)\) where \(\ln\) is the natural log (base-\(e\))
Write the following expressions in terms of \(y\), not \(\log(y)\). Simplify as much as possible:
- \(\log_2(y) = 1 - 3x\)
- \(\log_{10}(y) = -2 + 0.4x\)
- \(\ln(y) = 1 - 3x\)
Write the following expressions in terms of \(y\) and \(x\), not \(\log(y)\) and \(\log(x)\). Simplify as much as possible:
- \(\log_2(y) = 1 - 3\log_2(x)\)
- \(\ln(y) = -2 + 0.4\ln(x)\)
- \(\ln(y) = 1 - 3\log_2(x)\)
Logarithmic model: Regression of \(Y\) on \(\log(x)\) obtains the following estimated mean of \(Y\): \[ \hat{\mu}(Y \mid x) = 1 - 3 \log_2(x) \]
- What is the change in estimated mean response if we double the value of \(x\)?
- What is the change in estimated mean response if we triple the value of \(x\)?
- What is the change in estimated mean response if we reduce the value of \(x\) by 20%?
Exponential model: Regression of \(\log_2(Y)\) on \(x\) obtains the following estimated median of \(Y\): \[ \hat{median}(\log_2(Y) \mid x) = -2 + 0.4x \]
- Write the median in terms of \(Y\) instead of \(\log_2(Y)\). Simplify as much as possible.
- What is the multiplicative change in estimated median response if we increase \(x\) by 1 unit?
- What is the percent change in estimated median response if we increase \(x\) by 1 unit?
- What is the multiplicative change in estimated median response if we decrease \(x\) by 2 units?
- What is the percent change in estimated median response if we decrease \(x\) by 2 units?
Power model: Regression of \(\log_2(Y)\) on \(\log_2(x)\) obtains the following estimated median of \(Y\): \[ \hat{median}(\log_2(Y) \mid x) = 1 -3\log_2(x) \]
- Write the median in terms of \(Y\) and \(x\) instead of \(\log\)s. Simplify as much as possible.
- What is the multiplicative change in estimated median response if we increase \(x\) by 50%?
- What is the percent change in estimated median response if we increase \(x\) by 50%?
- What is the multiplicative change in estimated median response if we reduce the value of \(x\) by 20%?
- What is the percent change in estimated median response if we reduce the value of \(x\) by 20%?
2.12 Examples: Transformations
2.12.1 Cars 2004
This is a dataset with stats taken from 230 car makes and models from 2004.
We are interested in modeling car’s city miles per gallon (city.mpg) as a function of its weight in pounds (weight).
cars <- read.csv("https://math.carleton.edu/kstclair/data/cars2004.csv")
summary(dplyr::select(cars, city.mpg, weight))## city.mpg weight
## Min. :10.00 Min. :1850
## 1st Qu.:16.00 1st Qu.:3185
## Median :18.00 Median :3606
## Mean :19.22 Mean :3738
## 3rd Qu.:21.00 3rd Qu.:4237
## Max. :60.00 Max. :7608library(ggplot2)
ggplot(cars, aes(x= weight, y = city.mpg)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE) +
geom_smooth(method = "loess", se = FALSE, linetype = "dashed", color="red") +
labs(title="City MPG vs. weight")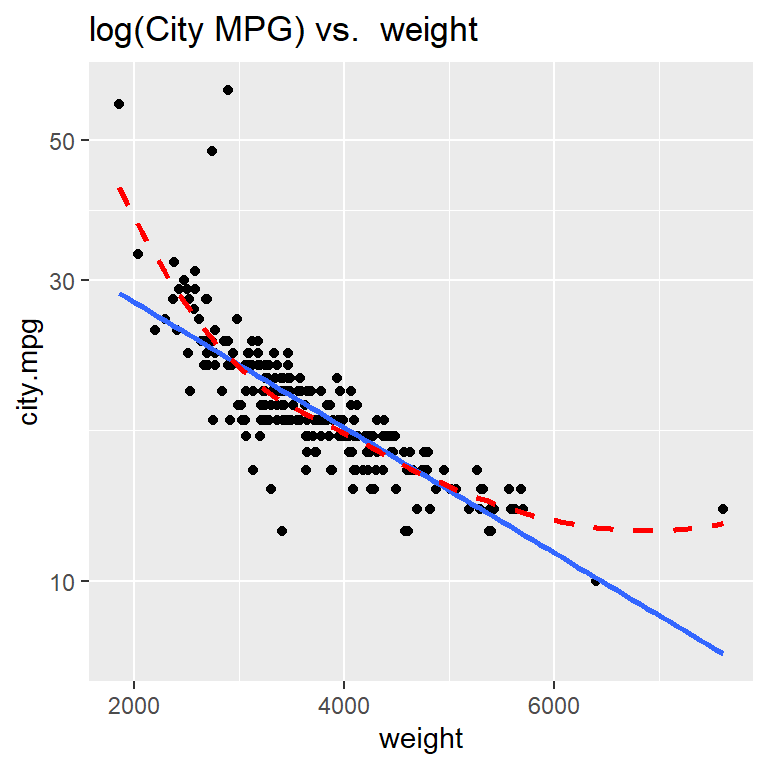
(R comment: I used the select command from dplyr to select only city mpg and weight in the code chunk above. Unfortunately, different versions of the select command are in both the dplyr and plotly packages. The latter is loaded to create interactive plots when using ggResidpanel. I used the :: operator above to specify which package the select command should be coming from.)
Hopefully it is clear that the relationship between city MPG and weight is not linear!
Explore some transformations: which gives the most linear relationship?
To do this, we can use ggplot’s scale functions to adjust transform one or both variables to a log or square root version.
Here is how we can create a scatterplot of the logarithm of city.mpg against weight using scale_y_log10() (since that is the axis we want to transform). Notice that using scale to transform a variable in a ggplot preserves the original units of the variable, meaning the numeric labels we see on the y axis below still represent measurements of city.mpg (and not log10(city.mpg))
ggplot(cars, aes(x= weight, y = city.mpg)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE) +
geom_smooth(method = "loess", se = FALSE, linetype = "dashed", color="red") +
scale_y_log10() +
labs(title = "log(City MPG) vs. weight")
Taking the logarithm of city MPG doesn’t improve the linearity of this scatterplot!
The grid of plots below were similarly transformed using either scale_?_log10() or scale_?_sqrt() to change a particular axis, where ? is eithe x or y depending on which axis is transformed.
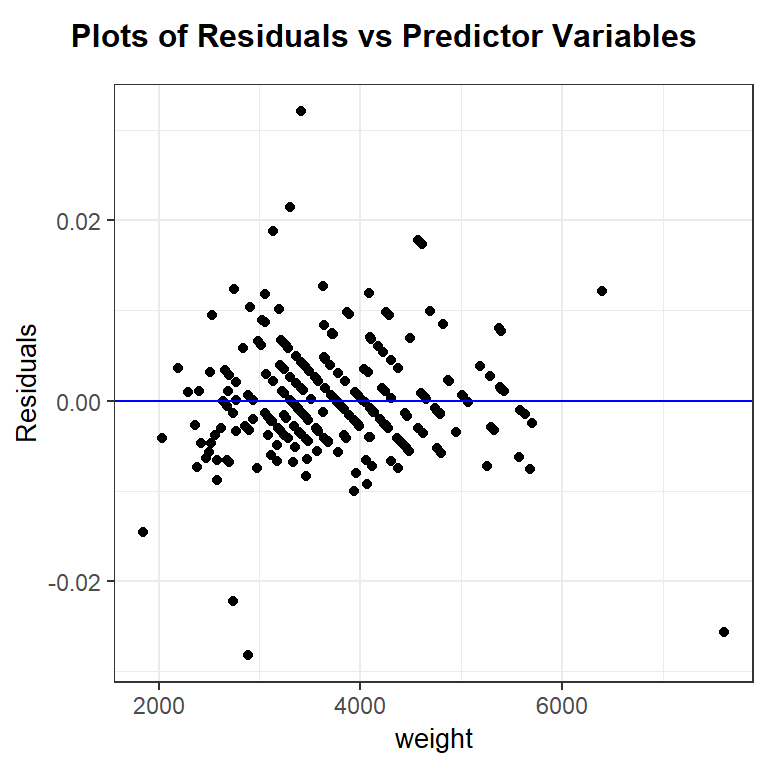
After trial-and-error, it looks like the reciprocal of mpg, or gallons used per mile, does have a roughly linear relationship with car weight. Let’s fit the regression of 1/city.mpg against weight and check diagnostic plots.
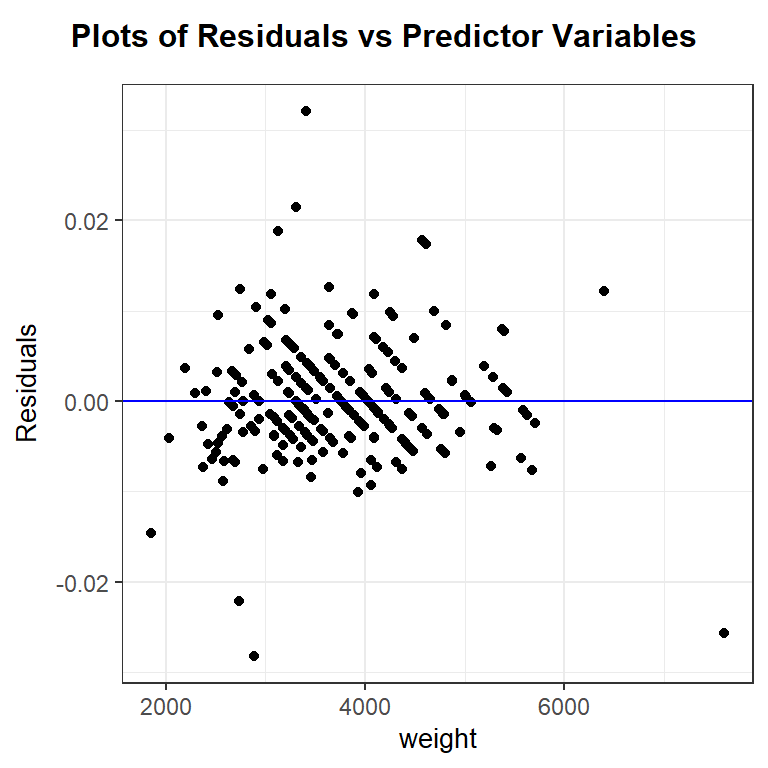
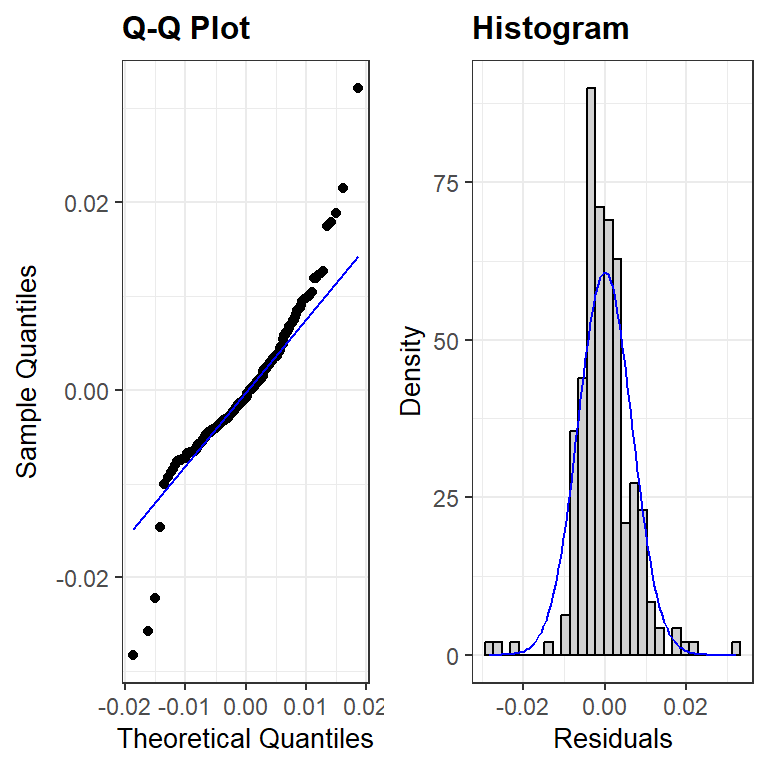
The linearity and constant variance assumptions look fine, though there are a some cases that are poorly modeled and have large magnitude residual values. The distribution of the residuals has slightly longer tails than a normal distribution and is slightly right skewed. This is likely due, in part, to the outliers noted in the residual plot. The effect of the noted outliers on the regression model fit should be explored before finalizing the model. (i.e. before making any inferential conclusions from the model)
## # A tibble: 2 × 7
## term estimate std.error statistic p.value conf.low conf.high
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 0.00952 0.00195 4.87 2.04e- 6 0.00567 0.0134
## 2 weight 0.0000122 0.000000509 24.0 2.23e-64 0.0000112 0.0000132For now, let’s assume that the outliers are not influencing our model fit (we will explore this question later in class). Since the inverse of MPG is gallons used per mile, our estimated model is
\[
\hat{\mu}(\textrm{gallons/mile} \mid \textrm{weight}) = 0.00952 + 0.0000122(\textrm{weight})
\]
Each 1 pound increase in weight is associated with an estimated 0.0000122 gallon/mile increase, on average. But, given the large scale of weight values, a 1 pound increase in a car’s weight is extremely small. Let’s consider a much larger increase in weight, like 1000 pound increase, to make better sense of this model. A 1000 pound increase in weight is associated with an estimated \(1000 \times 0.0000122 = 0.0122\) gallon/mile increase, on average. We are 95% confident that a 1000 pound increase in a car’s weight is associated with an increase in mean fuel consumption of 0.0112 to 0.0132 gallons per mile.
Extra R note: The I() function is a “as is” function needed when you to a math operation on the RIGHT hand side of a formula (~). Without the I() function, math operation like +, ^, /, or - on the right side of a formula are used to specify a specific model structure not an arithmetic operation. e.g. y ~ x-1 tells R to fit a linear model without an intercept (the -1 part), while y ~ I(x-1) tells R to fit the (usual slope & intercept) regression of \(y\) on \((x-1)\).
2.12.2 2005 Residential Energy Survey (RECS)
RECS surveys households across the US. We are treating this sample of 4,382 households as an equally-weighted sample of US households. Our goal now is to model total energy costs (CostTotal) as a function of the size of the housing unit (SqftMeasure).
(a) Total energy cost vs. size
With over 4,000 cases, we reduce point transparency with alpha to avoid overplotting. Assess the scatterplot in terms of (1) linearity, (2)constant variance, and (3) normal errors.
## [1] 4382 16## CostTotal SqftMeasure
## Min. : 57 Min. : 167
## 1st Qu.: 1138 1st Qu.: 1056
## Median : 1673 Median : 1848
## Mean : 1841 Mean : 2284
## 3rd Qu.: 2331 3rd Qu.: 3042
## Max. :10346 Max. :11383
## NA's :1library(ggplot2)
ggplot(energy, aes(x = SqftMeasure, y = CostTotal)) +
geom_point(alpha = .1) +
geom_smooth(method = "loess", se = FALSE)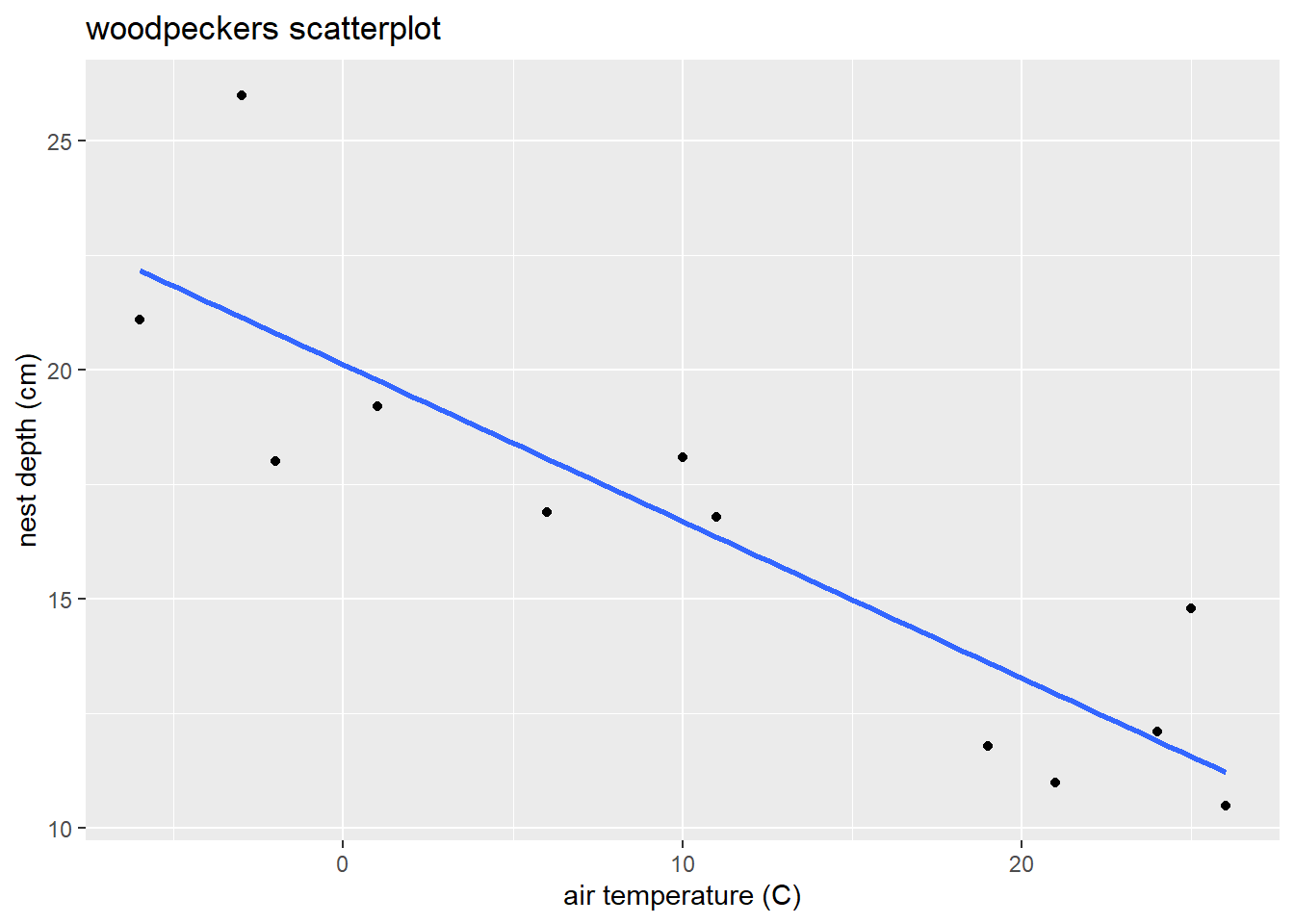
(R comment: I used the select command from dplyr to select only cost and square foot in the code chunk above. Unfortunately, different versions of the select command are in both the dplyr and plotly packages. The latter is loaded to create interactive plots when using ggResidpanel. I used the :: operator above to specify which package the select command should be coming from.)
(b) Find a transformation that yields a linear model Let’s just consider log transformations to see if we can find transformation(s) that yield a linear relationship. Create scatterplots of the following relationships and decide which one is “most linear”:
- total cost against log of square footage
- log of total cost against square footage
- log of total cost against log of square footage
(c) Fit the SLR of log of square footage against log of total cost and check diagnostic plots
(d) Use your fitted model to answer:
- What is the fitted model?
- How does cost change if house size is doubled? Get a CI for this effect.
- How does cost change if house size decreases by 10%? Get a CI for the effect.
2.13 \(R^2\) and ANOVA for SLR
After we check the fit of a model and determine that there are no concerns with the SLR assumptions, we can summarize it with inference, interpretations and measures of “strength” of the association. One common measure of strength is called “R-squared”: \[ R^2 = 1- \dfrac{(n-2)\hat{\sigma}^2}{(n-1)s^2_y} \] \(R^2\) measures the proportion of total variation in the response that is explained by the model. Total variation in \(y\) is measured, in part, by the sample SD of the response, which is a piece of the denominator above. The numerator measures the varation in \(y\) around the regression line (\(\hat{\sigma}\)), which is a measure of unexplained, or residual, variation. One minus the unexplained variation proportion gives us the value of \(R^2\).
2.13.1 Example: \(R^2\)
Let’s revisit the woodpecker nest depth model:
wpdata<- read.csv("https://math.carleton.edu/kstclair/data/woodpeckers.csv")
library(ggplot2)
ggplot(wpdata, aes(x = temp, y = depth)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE) +
labs(x = "air temperature (C)", y = "nest depth (cm)",
title = "woodpeckers scatterplot")
We get \(R^2\) in the Multiple R-squared entry in the lm summary output:
##
## Call:
## lm(formula = depth ~ temp, data = wpdata)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.8066 -1.3321 -0.6529 0.6811 4.8512
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 20.12228 0.94024 21.401 1.11e-09 ***
## temp -0.34218 0.05961 -5.741 0.000188 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.335 on 10 degrees of freedom
## Multiple R-squared: 0.7672, Adjusted R-squared: 0.7439
## F-statistic: 32.96 on 1 and 10 DF, p-value: 0.0001875Here we have \(R^2 = 0.7672\), meaning the regression of depth on temp helps explain about 76.7% of the observed variation in depth. We can see how R computes this value by looking at the sample SD of \(y\), \(s^2_y = 4.6133124\) and the estimated model SD \(\hat{\sigma} =2.3345298\)
## [1] 4.613312## [1] 2.33453## [1] 0.2327986## [1] 0.76720142.13.2 ANOVA for SLR
Analysis of Variance (ANOVA) decomposes the total variation in \(y_i\), \(y_i - \bar{y}\), into a portion that is explained by a model, \(\hat{y}_i - \bar{y}\), and a portion that is unexplained, \(y_i - \hat{y}_i\):
\[
y_i - \bar{y} = (y_i - \hat{y}_i) + (\hat{y}_i - \bar{y})
\]
For row 2 in the wpdata, the total variation is show in red in the plot below while the explained variation is in blue and unexplained in green. Notice that the “explained” portion is what gets us closer to the actual response \(y=26\) (compared to just the mean response), which is what you would expect to see if temp is useful in explaining why we see variation in nest depths.
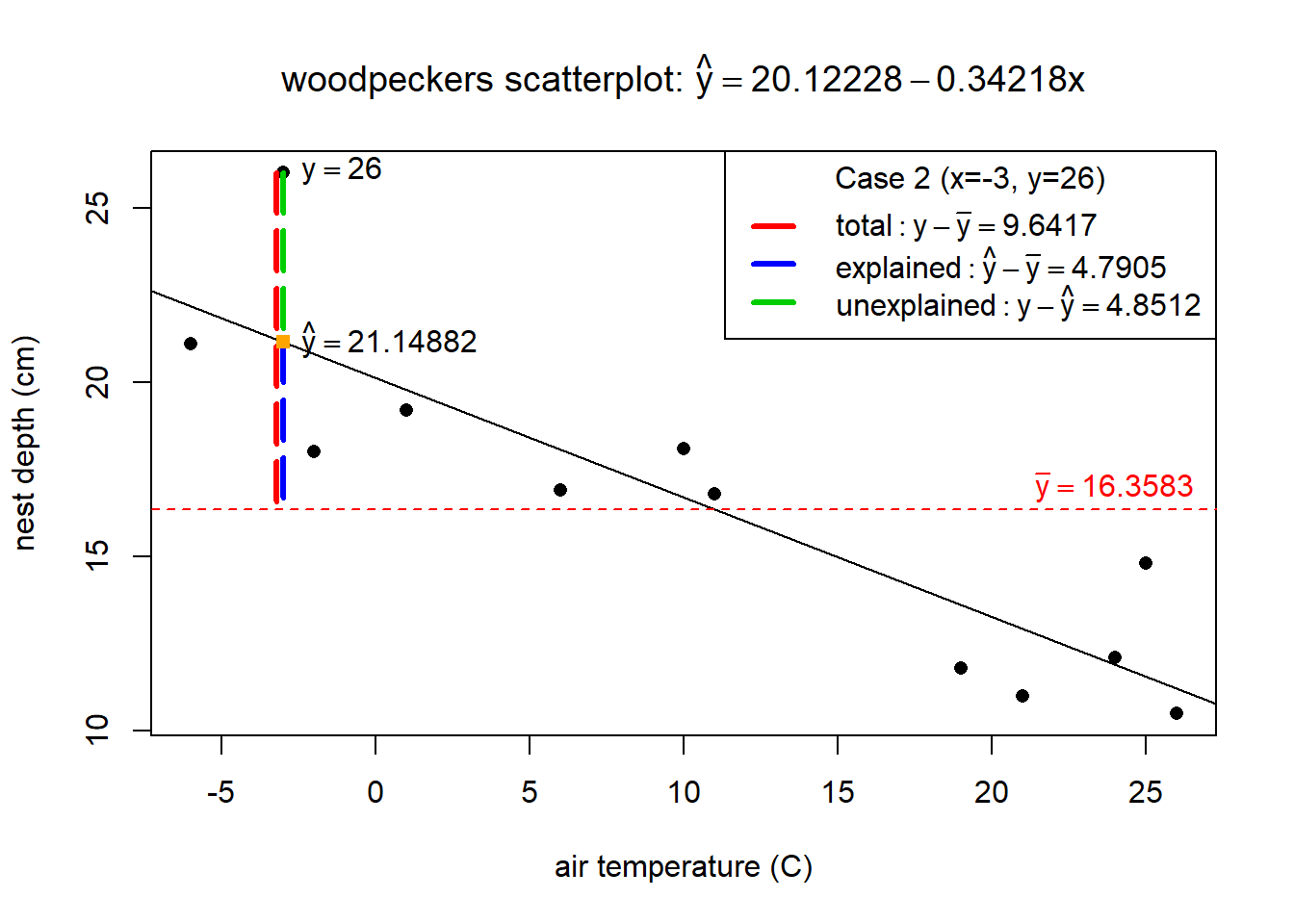
The next step in ANOVA, is to total the squared variation distances across all \(n\) data points (squared because we don’t care if the differences are positive or negative). Some very useful mathematics is used to prove that the total squared variation of all \(n\) cases is equal to \[ \sum_{i=1}^n (y_i - \bar{y})^2 = \sum_{i=1}^n (y_i - \hat{y}_i)^2 + \sum_{i=1}^n (\hat{y}_i - \bar{y})^2 \]
The three components are called:
- total variation: \(SST = \sum_{i=1}^n (y_i - \bar{y})^2 = (n-1)s^2_y\)
- regression (explained) variation: \(SSreg = \sum_{i=1}^n (\hat{y}_i - \bar{y})^2\)
- residual (unexplained) variation: \(SSR = \sum_{i=1}^n (y_i - \hat{y}_i)^2 = (n-2)\hat{\sigma}^2\)
These sum of squares (SS) can also be used to compute \(R^2\) since \[ R^2 = 1- \dfrac{(n-2)\hat{\sigma}^2}{(n-1)s^2_y} = 1- \dfrac{SSR}{SST} = \dfrac{SSreg}{SST} \]
2.13.3 Example: ANOVA
Back to the nest depth model. The anova function extracts the sum of square values from our lm:
## Analysis of Variance Table
##
## Response: depth
## Df Sum Sq Mean Sq F value Pr(>F)
## temp 1 179.61 179.61 32.956 0.0001875 ***
## Residuals 10 54.50 5.45
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1For this model we have
- regression (explained) variation: from the temp row, \(SSreg = 179.61\)
- residual (unexplained) variation: from the Residuals row, \(SSR = 54.60\)
- total variation: adding the two SS values gives total variation \(SST = SSreg + SSR = 179.61 + 54.60 = 234.21\)
The ANOVA SS can also give us the value of \(R^2\) for the model: \[ R^2 = \dfrac{179.61}{179.61 + 54.60} = 0.7668759 \]